
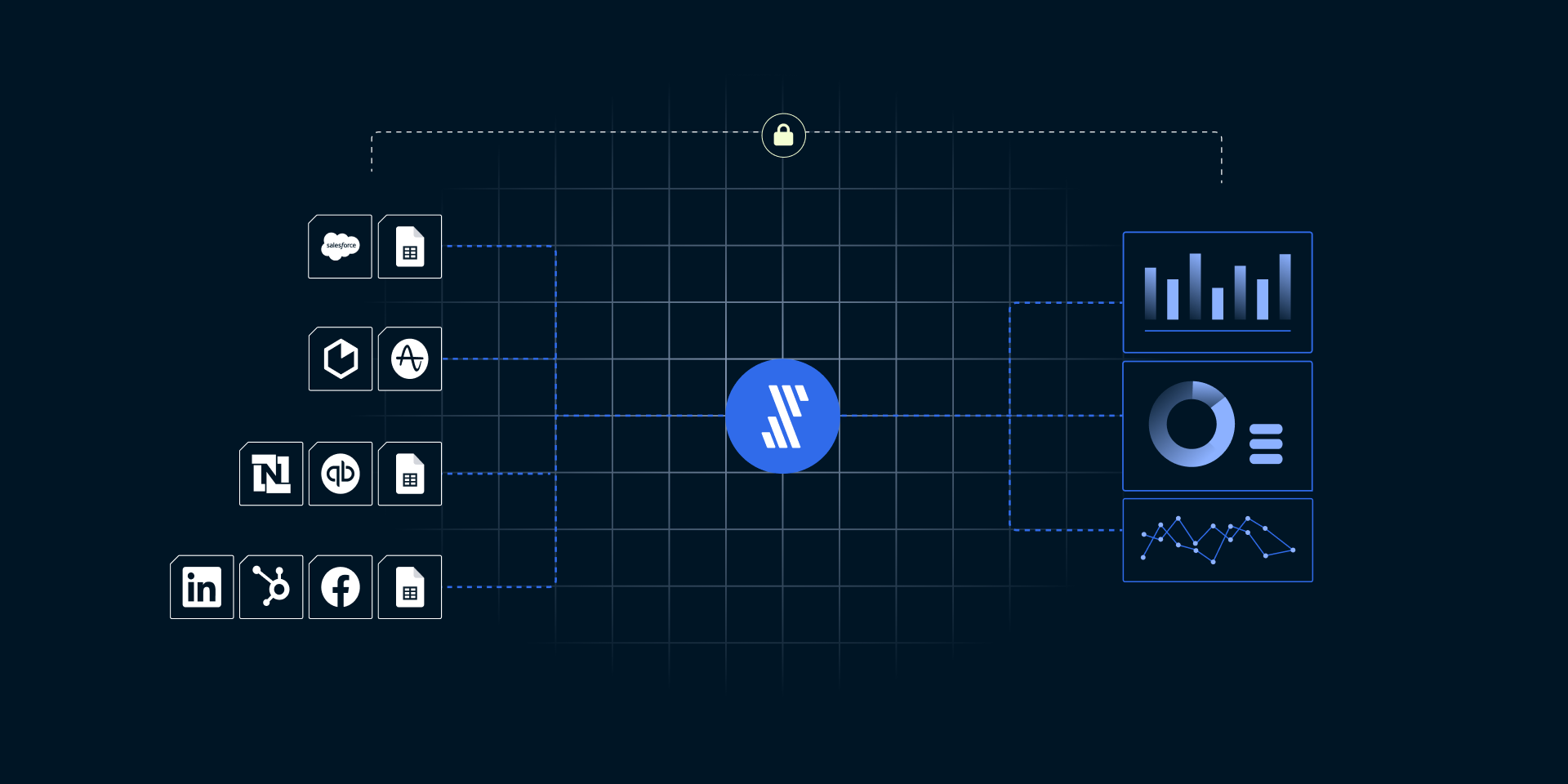
Data teams field requests from across the organization when business initiatives require the centralization, movement or integration of data across platforms. These requests, while critical, are arduous and onerous for engineers. Companies report spending $520K annually for engineers to build and maintain data pipelines, accounting for 44 percent of their working hours. On the other side of the data team, analysts report spending 34 percent of their time accessing data and less than half of their time actually analyzing it.
So how can data leaders free their team from time-consuming ad-hoc requests? They need to enable data democratization.
Balancing data access with data compliance
At a glance, the solution is simple: easier, faster access to data — that’s if data wasn’t such a valuable and litigious asset.
Privacy and security considerations are integral as the collection, use, storage and sharing of data grow more complex. Instances of data breaches, unauthorized access and theft of sensitive information lead to financial and reputational repercussions. Data and security teams navigate a complex landscape of data protection and privacy laws to ensure proper data governance and maintain transparency in their data-related activities to mitigate risk.
Centralizing data at scale is vital to weaving a data mesh, with a single source of truth and layered datasets to calculate holistic and accurate metrics to power the entire organization. However, data is most vulnerable once it’s left its home source. Replicating data without the proper monitoring, security and control practices risks putting the wrong data into the wrong hands.
The danger of shadow analytics
Under pressure to drive results, employees across the company crave fresh, reliable data to inform their decision making. Waiting in a long queue for every new data integration request grows time consuming and delays business impact. These delays can lead to the formation of rogue data teams that bypass official procedures.
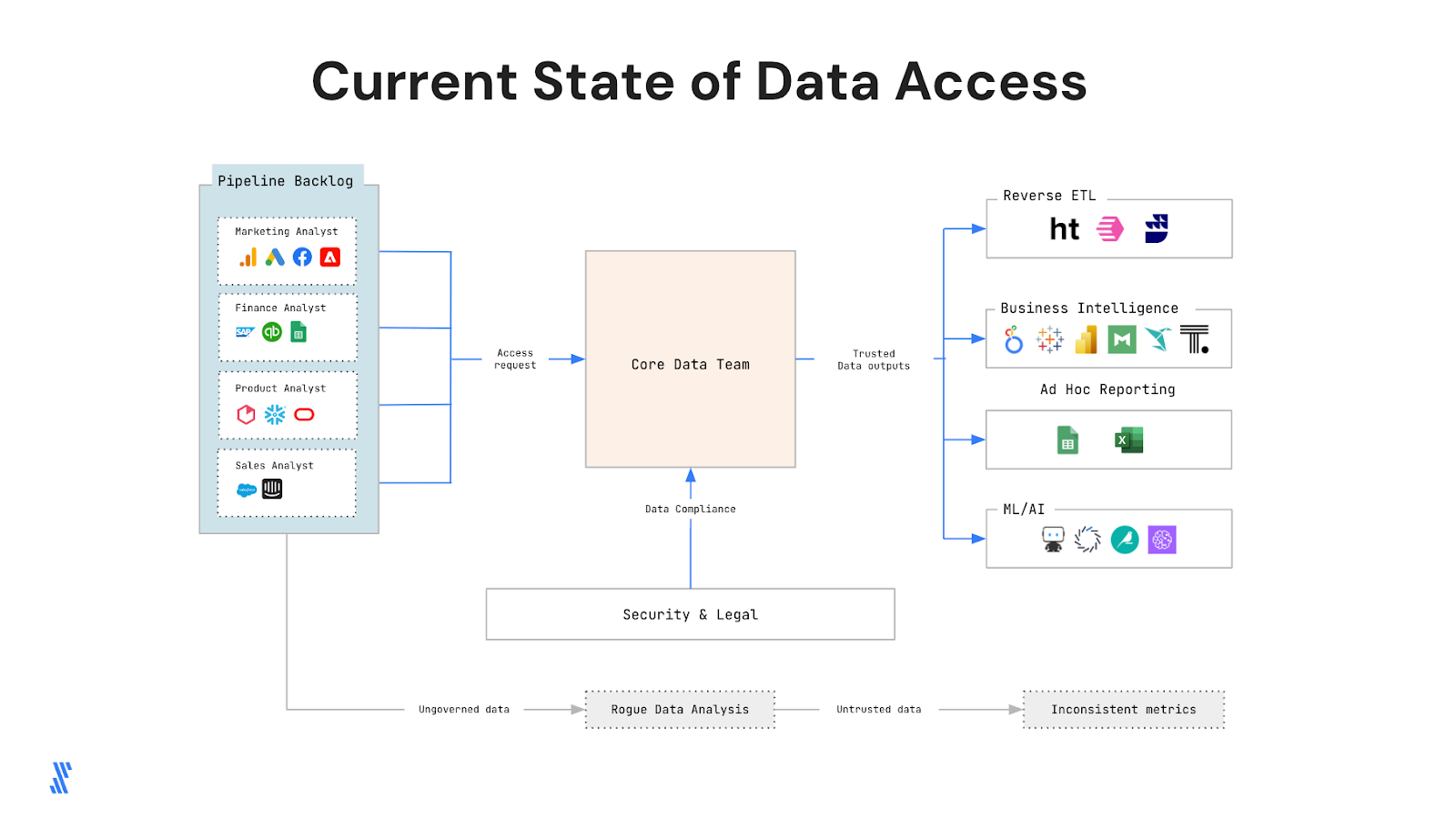
Rogue data teams, also known as shadow analytics, emerge independently, outside the purview of the central data team, and operate with the intention of addressing their immediate data needs. While well-intentioned, rogue data teams aren’t trained or held accountable for data protection in the same way data professionals are. They might ignore the operations and policies the data team follows, with their actions invisible to data and security teams. Ultimately, these rogue data teams leave the company vulnerable to damages due to the mishandling of sensitive data. That makes it that much more important to enact a data mesh strategy with improved, but secure, data access across the organization.
How to enable safe self-service data access
Governed data movement is the solution — and the integral ingredient to enabling self-service data access at scale.
Governed data movement is the practice of moving or replicating data with control over how and where it’s replicated and visibility into where it came from, its source owner and who has access.
Within a modern data stack, governed data movement is built into your infrastructure — enabling easier but secure data access. A few different configurations exist to safely provide data autonomy for power users across the company, allowing them to access data in a way that’s efficient, visible to the core data team and suits the needs of the individual’s motivations and technical abilities.
- Self-service dashboards: Traditionally, data is accessed by employees via pre-built dashboards. The majority of users consume data with the help of pre-defined metrics and reports provided by analysts.
- Self-service datasets: Where data is needed in a more exploratory format, cleaned data is pushed to ‘shoppable’ cloud data marts or exploration in a BI platform.
- Self-service pipelines: In the case of less complex data sources that hold less sensitive data, self-service pipelines allow distributed analysts or power users to own their data from creation to consumption, by managing their own integrations.
Determining the best self-service strategy for each user or department depends on both the sensitivity of the data and the end user. For example, data containing PII carries a higher risk of damages in the case of a malicious or accidental security breach than data without PII. In a similar nature, employees with more training and security clearance are less likely to misuse data than employees with less education and clearance.
By combining resources and training with the right technology and governed data strategy, data teams can safely share their workload with teams outside of their own, without sacrificing their visibility and control over the handling of data at their company.
Why this matters to the marketing team
Marketing is a great candidate for self-service data pipelines. Especially in enterprises with distributed data teams, where the analyst and source owners sit closer in the organization than the central IT or data team.
Marketing teams are unique in that they use more tools and make faster decisions than any other team. Marketers rely on data to make educated assumptions about a campaign’s performance and how changes to the campaign might affect future performance. Due to the nature of their role, marketing teams have unique priorities when it comes to data. Most of the time, marketing teams value speed over absolute accuracy, where another team like finance would forgo speed for more confidence in their reporting.
Marketers need to understand their customers’ behaviors and interactions with their brand, while their leaders need to understand the ROI tied to each customer engagement and their impacts on conversions. But, building a comprehensive Customer 360 and accurately tracking marketing attribution is a laborious task without the right solutions and processes — especially when the sources and required information changes frequently.
How to enable a self-service Customer 360
When marketing tools and programs change rapidly, the pipeline owner can turn into a roadblock to getting dashboards updated to measure the effects. Fortunately, the nature of the data is fairly low risk because it’s heavily event-based and any present PII is easily blocked or hashed without compromising its analytic value.
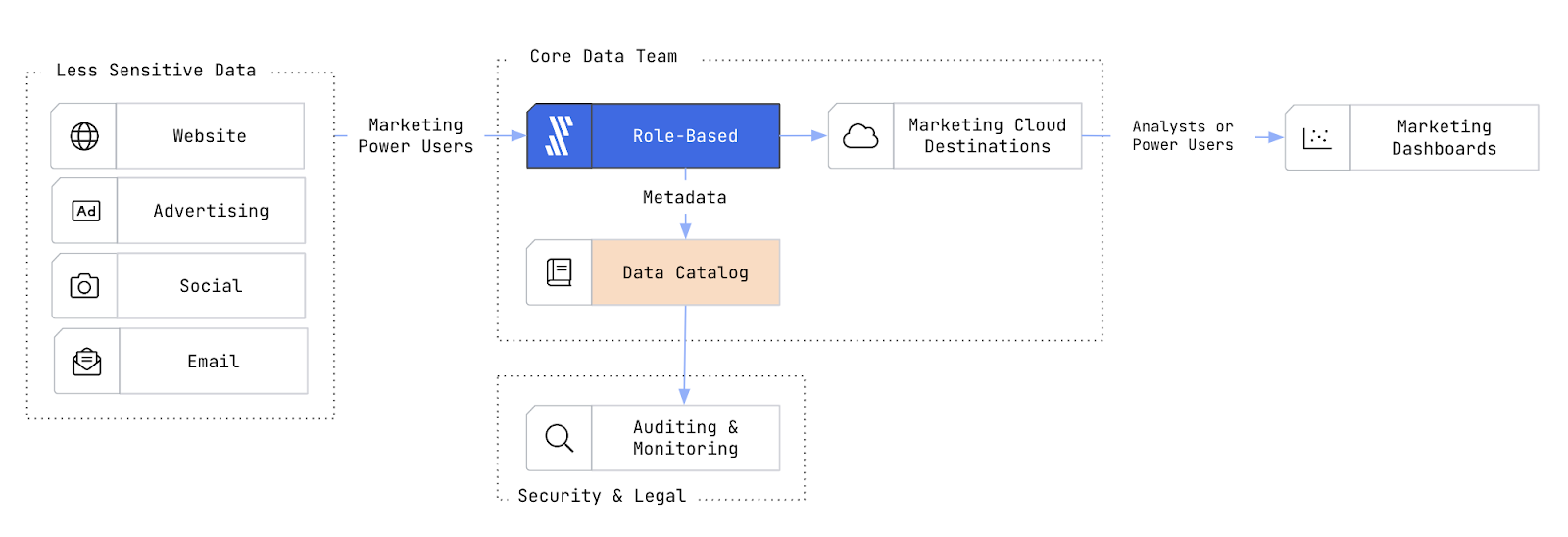
A cloud data platform, like Fivetran, makes providing this level of self-service customer view exponentially easier. It’s easy to use and completely code-free, opening the door for non-engineers to spin up their own pipelines. Granular and scalable access control settings give users access to their necessary data and nothing else, allowing data teams to safely democratize data without exposing sensitive information to the wrong audience.
If select marketing members have restricted access to their own pipelines, the marketing organization can onboard new tools and add or modify the data for analysis more efficiently without rush requests to the central data team. For visibility into the handling of marketing data, metadata from the whole process is monitored by the core data team and audited for compliance.
How Fivetran helps:
- RBAC: Set destination and connector level access and preconfigure team settings for faster onboarding
- Automated user provisioning: Integrate with Okta or Azure AD SCIM providers for streamlined user management across systems
- Fivetran Transformations: Boost reporting capabilities by delivering analytics-ready data to downstream users with free Quickstart data models and integrated scheduling for baked-in automation
- Metadata sharing: Track metadata on data moved with Fivetran via the Fivetran Platform Connector or native integrations with many catalog and quality tools including Alation, Atlan, Collibra, Monte Carlo, Data.world and more
Learning from Care.com and their hybrid self-service strategy
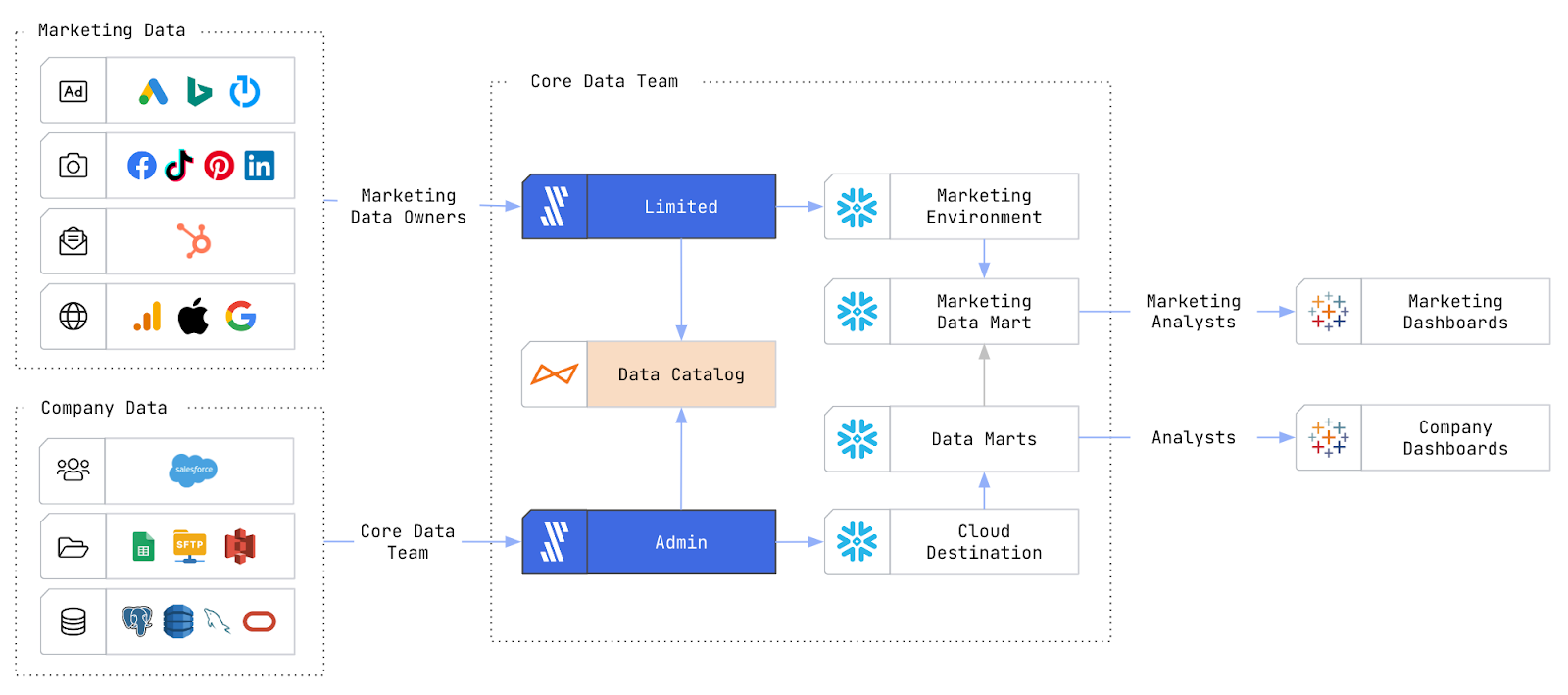
Care.com, a global online marketplace for varying care services, leverages Fivetran, Snowflake and dbt to serve leadership and teams across the data-driven organization with access to fresh, relevant data.
The core data team manages the movement of company data from databases and sensitive sources, while power users on the marketing team have unique Fivetran access that allows them to onboard new marketing sources and make changes to their existing pipelines without going through the core data team.
This significantly reduces their time to insights and refocuses engineering hours to advanced transformations and more technical, business critical initiatives — without sacrificing governance, security and visibility over the organization’s data movement.
With this 360-degree view of their customer, marketing leaders can monitor conversions hourly and act on increases and decreases in performance as they arise. For example, when they see a spike in conversions, they can immediately take action to uncover the source — maybe they sent an email with a compelling CTA or maybe an ad is performing exceptionally well — and really understand and act on the effects of their marketing efforts in real time.
With company data out of legacy databases and into new Snowflake environments, engineers more efficiently share clean, queryable data with analysts via domain-specific data marts.
Leveraging a modern data stack, Care.com has democratized data access — at scale. This has expedited the impact of data on their customer experience and enabled improved customer outcomes.
[CTA_MODULE]












%20(1).png)

.svg)
.svg)
.svg)