

Building data applications is crucial for getting the most value possible out of your data, but DIY approaches can be time-consuming and complex. This post will explain how Fivetran’s data movement platform helps accelerate building data applications in the Snowflake Data Cloud with Streamlit.
I'll set up a Workday HCM to Snowflake connector to move several hundred tables that include candidate, compensation, job, organization and employee information over to Snowflake so that my Workday dataset can be centralized with other critical data, including SAP and Salesforce, to enable the wide range of data workloads that Snowflake supports. I’ll then show you how to create a simple Streamlit talent management application.
It’s worth pointing out that most operational systems and ERP platforms like Workday have their own operational analytics capabilities. For Workday, it has services like Workday Prism Analytics and People Analytics.
But what if you want to combine Workday with other data sources to improve your customer experience? For example, you might combine demographic data from Salesforce, SAP ERP purchasing behavior and Workday employee interactions to identify segments or clusters with similar characteristics and needs.
That's where Fivetran's automated data platform comes in. It allows you to centralize all of your data, modernize your data infrastructure, achieve greater data self-service and democratization, and build differentiating data solutions in the Snowflake Data Cloud with Streamlit.
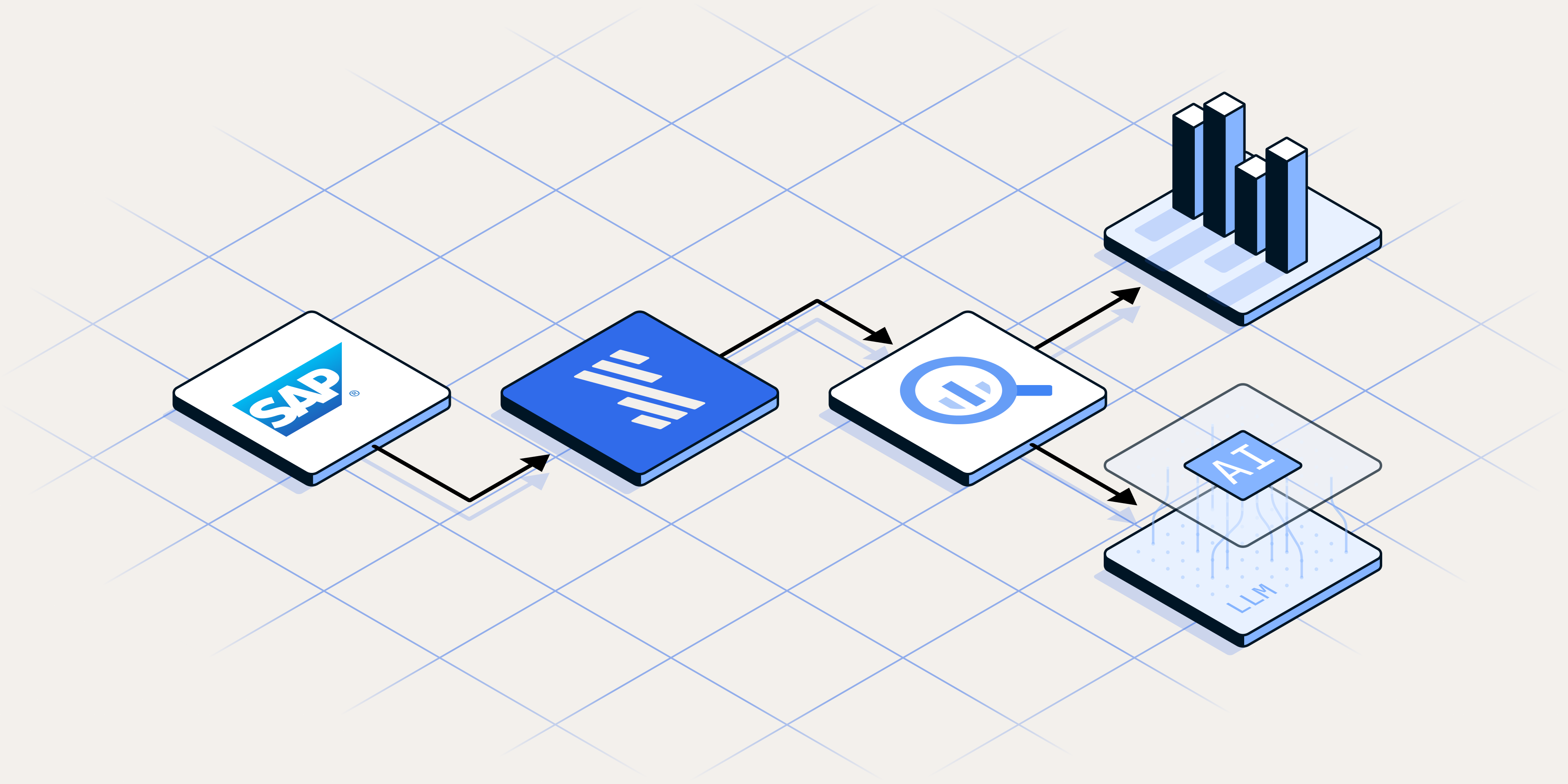
Below is a high-level architecture for my Snowflake data workload today, which involves building and creating new data solutions. I’ll move a Workday HCM data set to the Snowflake Data Cloud and then quickly build a simple Streamlit talent management application that leverages the new Workday dataset.
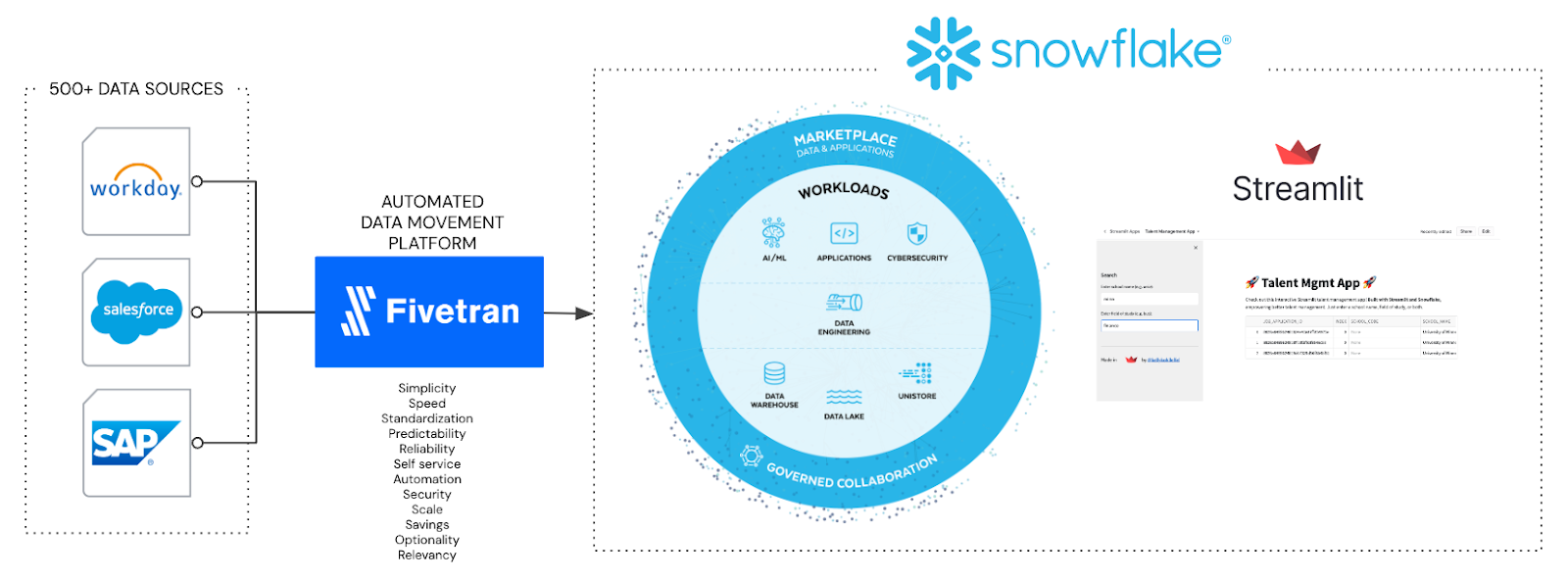
What you'll see today from Fivetran, Snowflake and Streamlit is pure SaaS, fully automated and fully managed. I’m also using Streamlit as a native app within Snowflake. For data movement on the front end, Fivetran is exceptionally fast to set up and configure in just a few minutes.
As a quick note, you can check out an end-to-end video of this solution with Fivetran, Snowflake and Streamlit on YouTube below.
So let's get Workday HCM data flowing into Snowflake and build a Streamlit talent management application.
Adding a new source connector with Fivetran
I have one Snowflake destination in this Fivetran account, but I could have multiple Snowflake destinations depending on my business requirements. Also, I have my choice of cloud providers and regions to select from for each Snowflake destination.
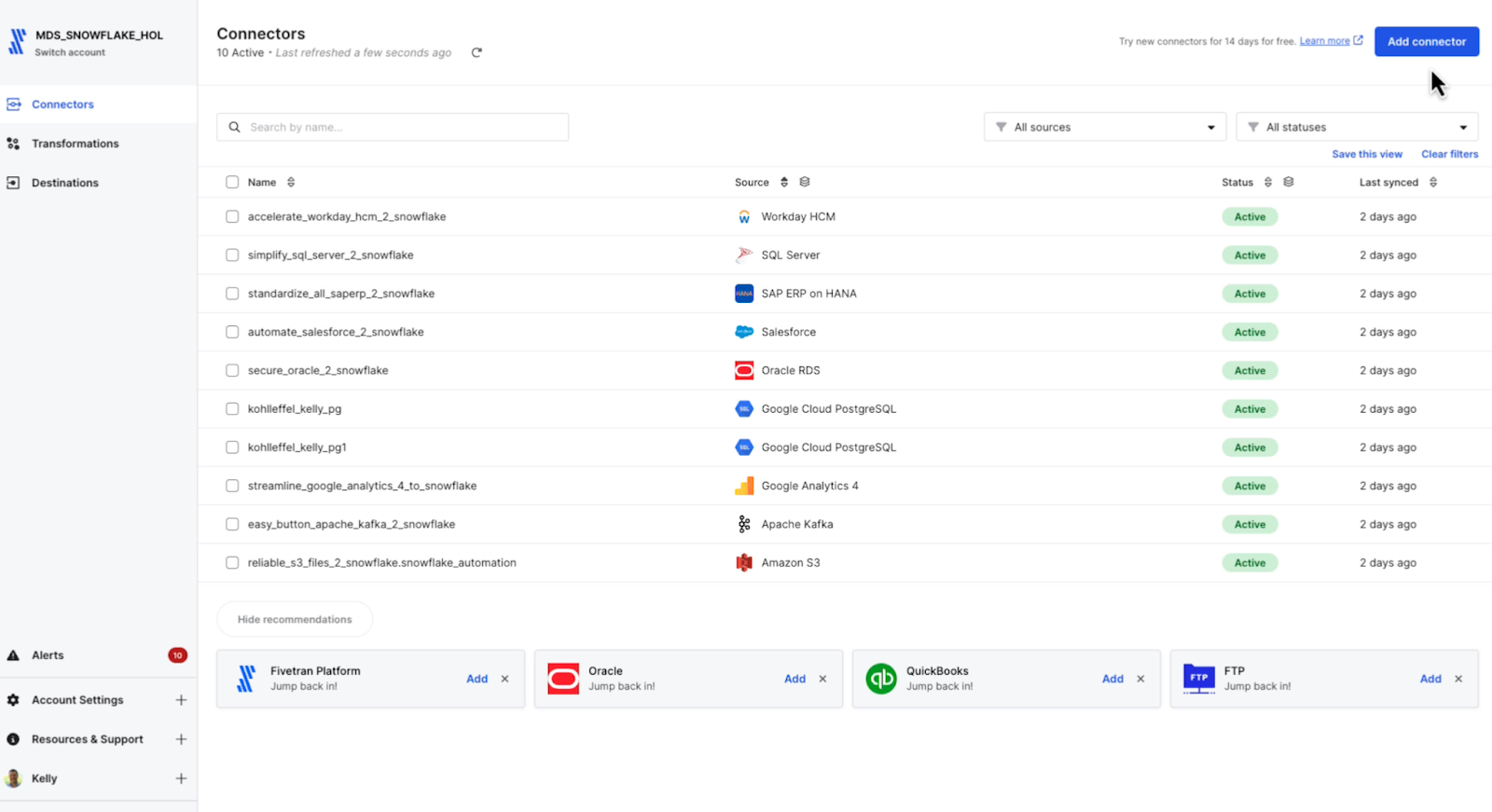
Multiple data sources already flow into the Snowflake Data Cloud, including SAP, SQL Server and Oracle operational databases. I also have Salesforce, GA4, Kafka and S3, and I have Workday HCM connectors.
Fivetran offers connectors to over 500 sources, including databases, applications, file systems and event systems, and that number is growing daily.
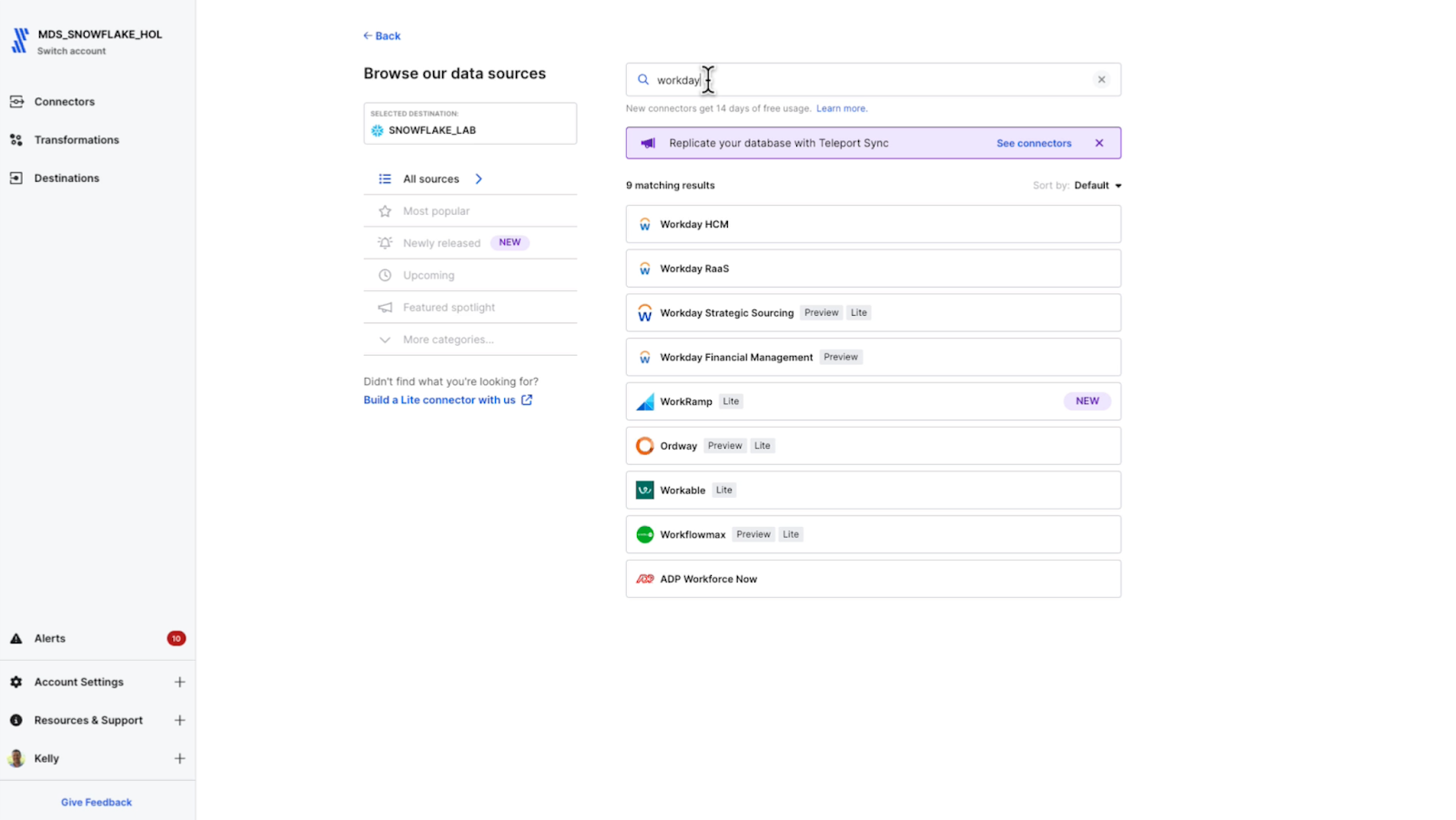
The talent management application I’ll build in Steamlit will use a different dataset from Workday HCM. I could add schemas and tables to my current Workday connector, but I’d like to show the full end-to-end setup, so I’ll simply set up a new one.
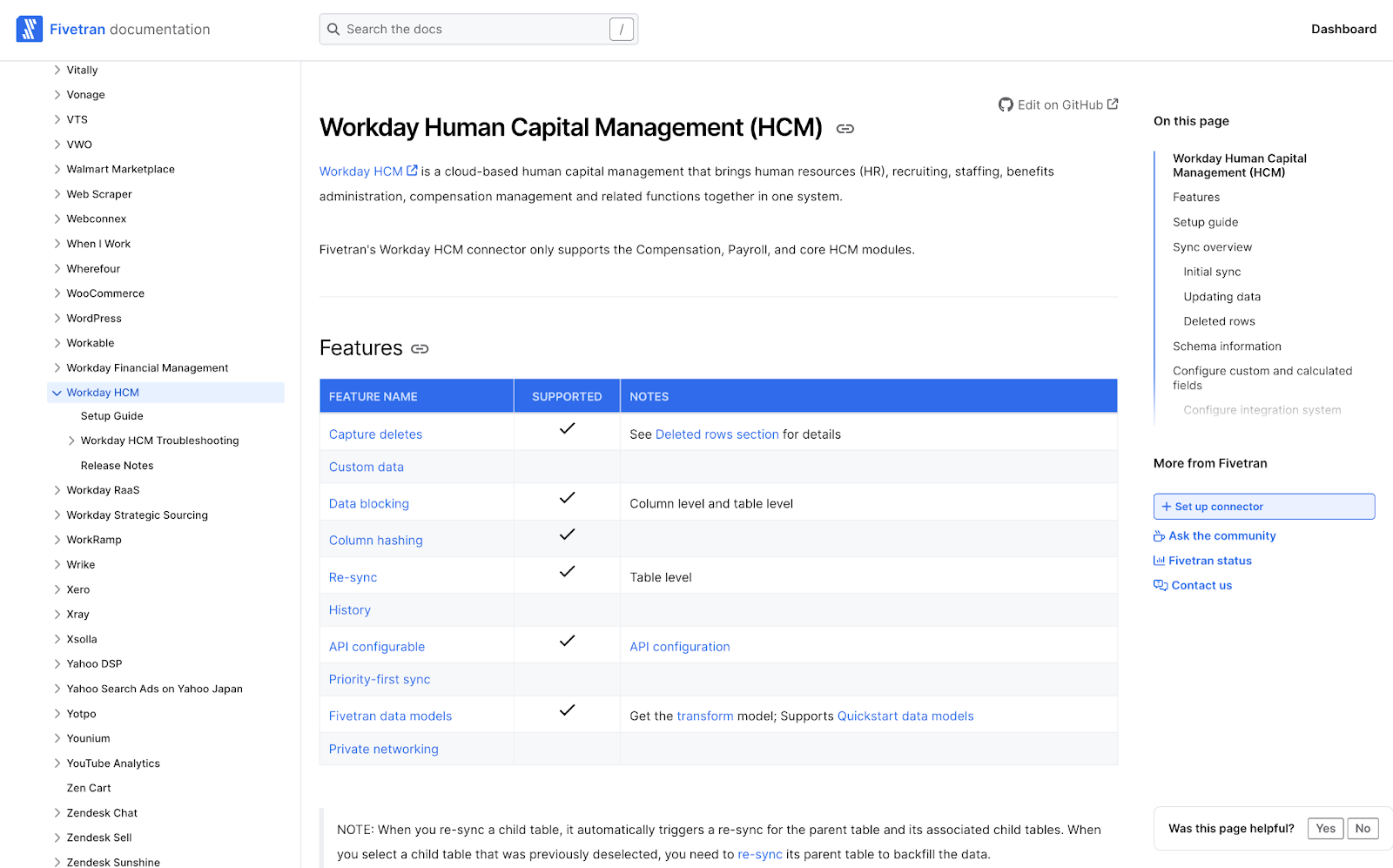
Fivetran supports Workday HCM, but Workday RaaS, Strategic Sourcing and Financial Management can also be set up as sources.
The Fivetran engineering, product and technical documentation teams do a fantastic job laying out the steps to get data flowing quickly into the Snowflake Data Cloud. I’ve linked it here as well if you’d like to take a look outside of the Fivetran UI: Workday HCM Setup Guide.
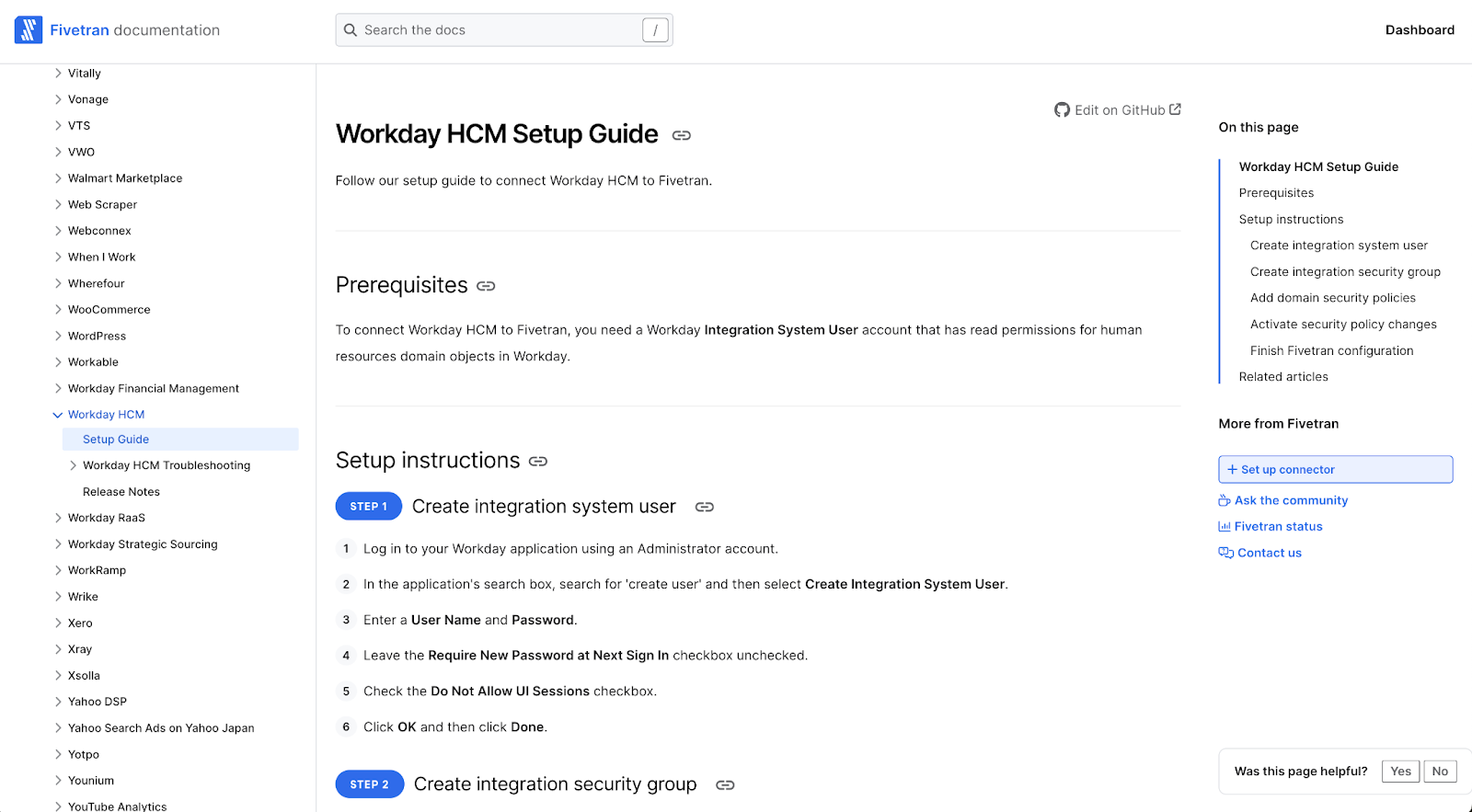
Additionally, for each source and destination, documentation includes details on version support, configuration support, feature support, any limitations, a sync overview, schema information, type transformations and much more. Here is the Workday HCM source detail page.
Importantly, in the Fivetran UI, any source setup pages are framed on the right by the setup guide in the gray navigation on the right side. It’s the fast path to ensuring you understand the options to connect quickly to any source with Fivetran.
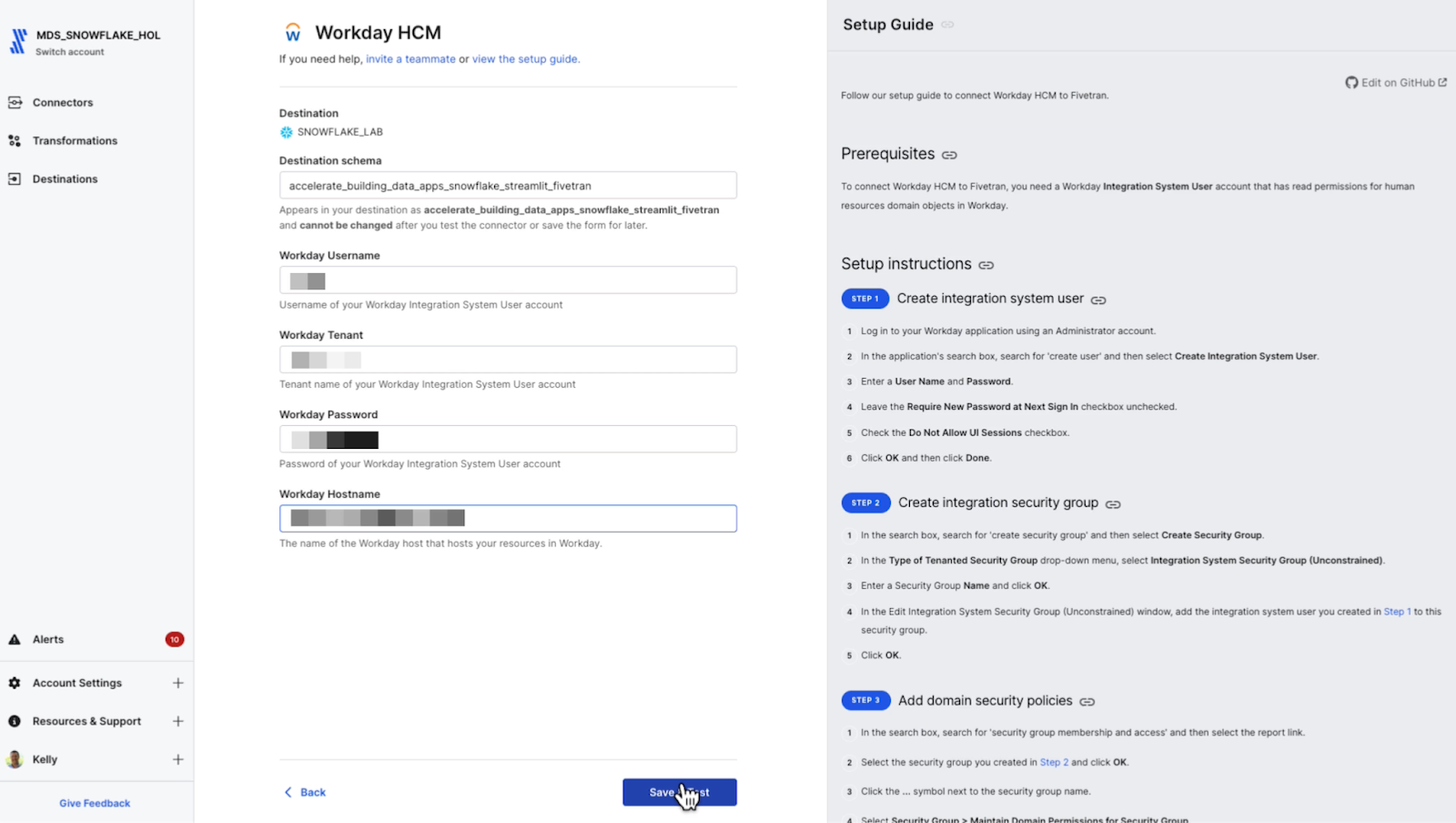
I can name the destination schema anything that I choose. Also, schemas and tables do not have to be created ahead of time in Snowflake. I’m going to use the following:
accelerate_building_data_apps_snowflake_streamlit_fivetran
From there, Fivetran must know how to authenticate to the Workday integration system API, so I’ll provide the username, the Workday tenant, the password and my Workday host identifier.
Fivetran needs those details to authenticate into Workday and will run connection tests to the Workday API, validate the authentication details and ensure that Fivetran can access the Workday API.
Managing source changes and schema drift plus security
Not only will Fivetran move the Workday data set I just selected and do the initial historical sync, but when there are any changes to those Workday tables or columns, CDC is automatically set up for me, 100% no code, so that any incremental changes are captured as well at whatever schedule I prefer.
From a security standpoint, all data in motion is encrypted. Any data at rest that sits ephemerally in the Fivetran service is also encrypted.
Once Fivetran has moved the data and completed its checks, no data is stored in the Fivetran service. Fivetran simply maintains a cursor at the sync point for the next incremental sync to capture changes.
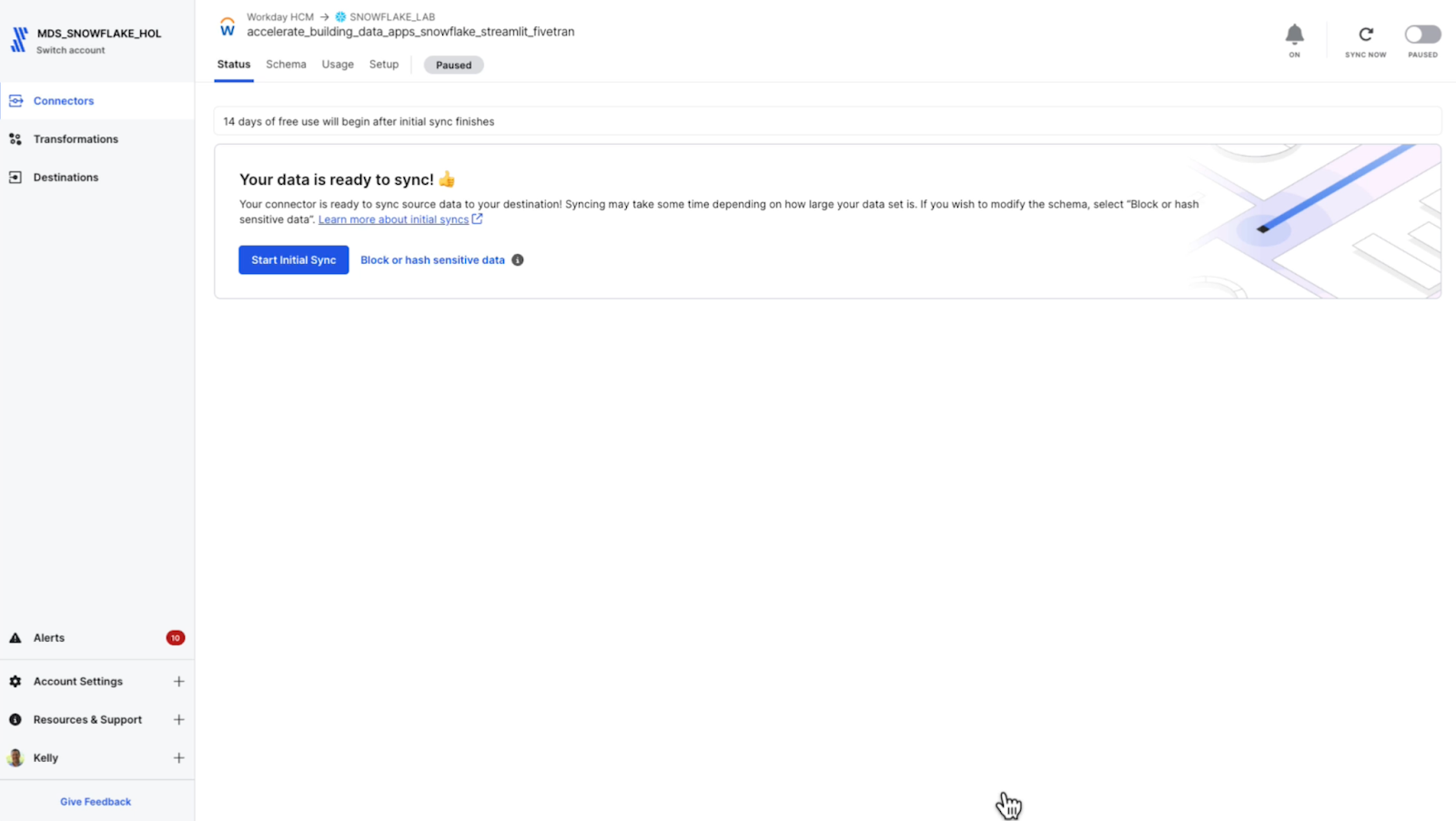
Starting the initial sync from Workday HCM to the Snowflake Data Cloud
That's it, I'm ready to start syncing my Workday HCM dataset to Snowflake. Fivetran provides a highly compelling degree of standardization and predictability for any source to the Snowflake Data Cloud that any data team can appreciate.
Highlighting Fivetran transformations
Fivetran provides seamless integration with dbt Core and dbt Cloud, including QuickStart data models. These allow you to automatically produce analytics-ready tables using pre-built data models and transform your data with no code, no additional dbt project and no additional third-party tools required.
Transformations include integrated scheduling, and they automatically trigger model runs after completing Fivetran connector syncs in Snowflake.
You can check out the wide range of connectors and packages that support quick-start data models or transformations for dbt here.
Of note, there is a Workday Fivetran Quickstart Transformation that models Workday HCM data based on the Fivetran connector and provides the following ready to use modeled data:
- workday__employee_overview – Each record represents an employee with enriched personal information and the positions they hold. This helps measure employee demographic and geographical distribution, overall retention and turnover, and compensation analysis of their employees.
- workday__job_overview – Each record represents a job with enriched details on job profiles and job families. This allows users to understand recruitment patterns and details within a job and job groupings.
- workday__organization_overview – Each record represents organization, organization roles and positions and workers tied to these organizations. This allows end users to slice organizational data at any grain to better analyze organizational structures.
- workday__position_overview – Each record represents a position with enriched data on positions. This allows end users to understand position availabilities, vacancies and cost to optimize hiring efforts.
A quick review of the Fivetran top navigation options
I’ll return to the Workday connector and the Schema tab across the top navigation.
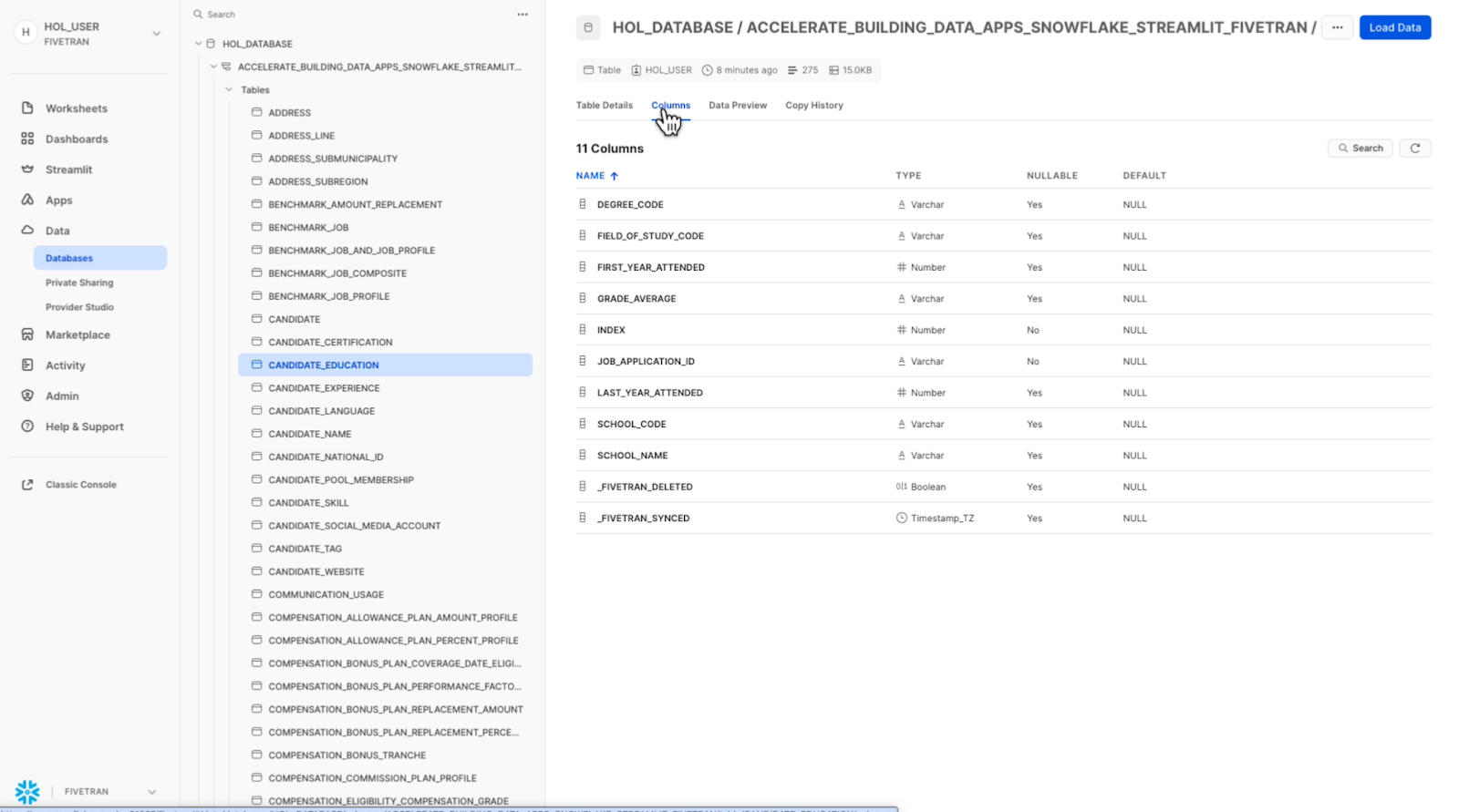
This Workday dataset has 200+ tables covering a range of objects in Workday HCM. My focus for the Streamlit app I will build is the Candidate Experience table.
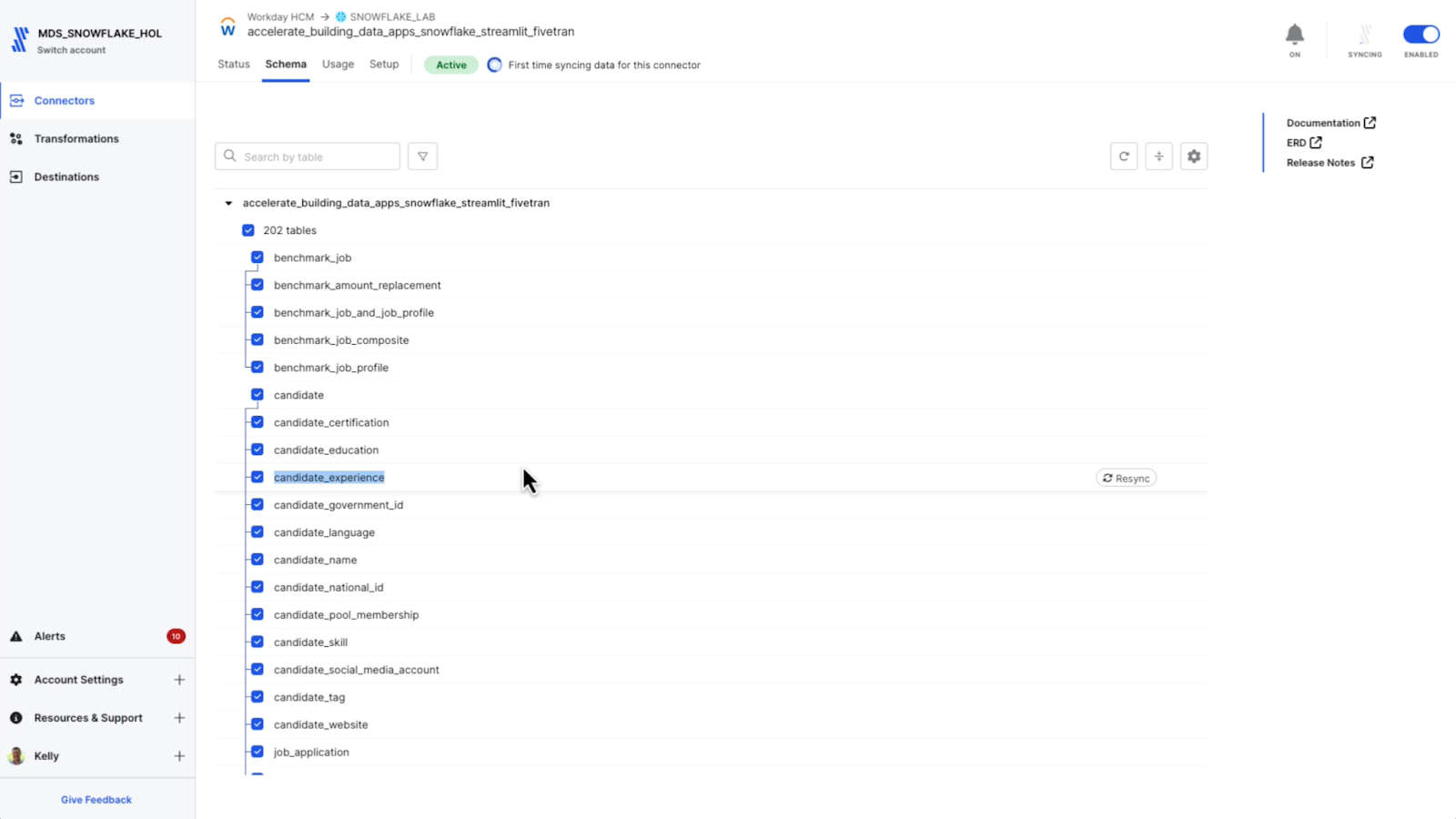
All initial syncs and the first 14 days of incrementals are free. On the Setup page, I can set the incremental sync frequency. The default for the Workday connector is every six hours, but I can choose from one minute up to 24 hours depending on my data product or downstream data application requirements.
Fivetran ERDs are gold
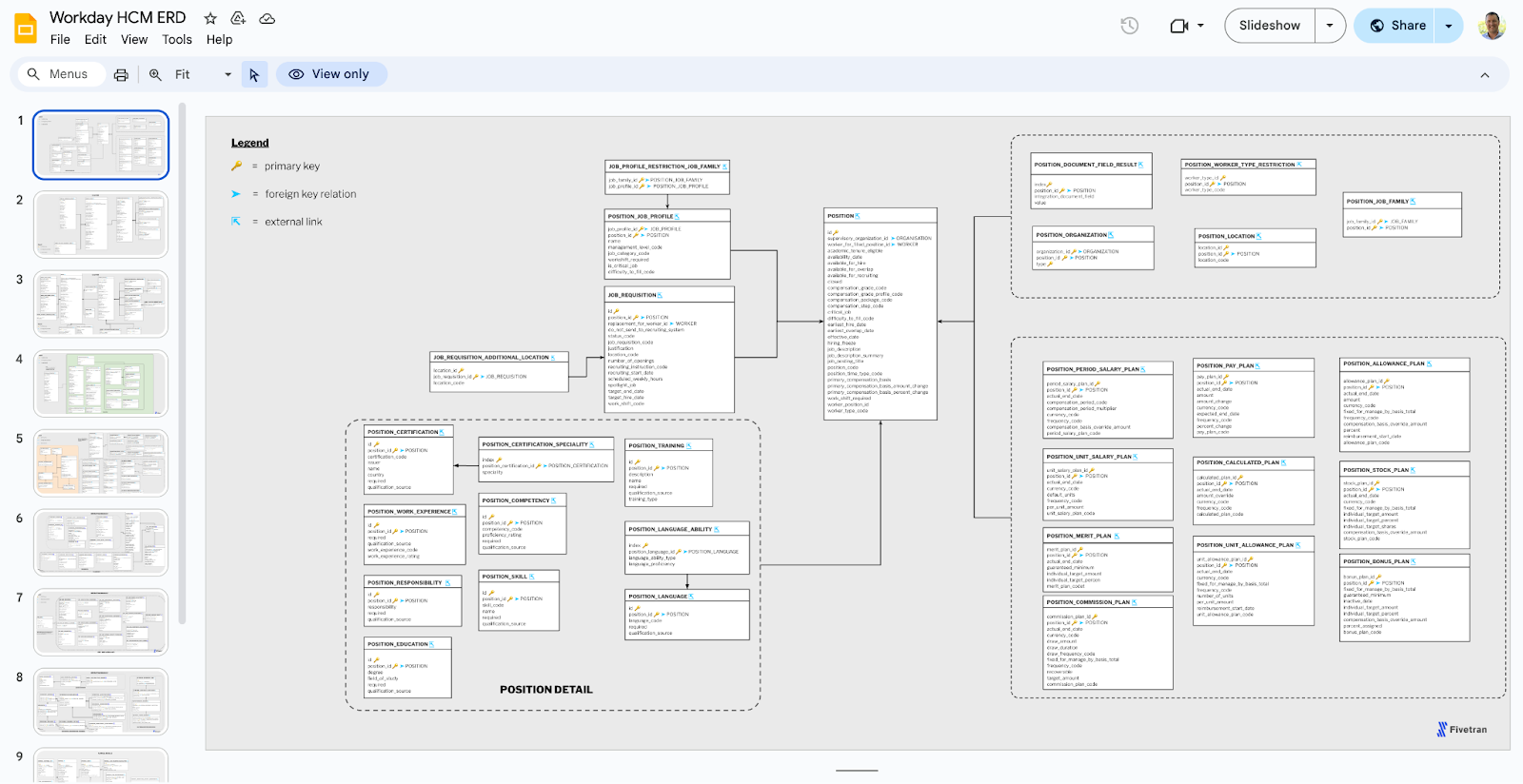
Let’s quickly review the Fivetran Docs. One part of Fivetran documentation I sometimes take for granted is the Entity Relationship Diagrams (ERDs). Fivetran provides these ERDs for most application connectors.
Here you're going to find detailed information and the blueprint for how each entity in Workday HCM, in this case, relates to the others.
The Workday connector is now on the list with the others, and I now have access to all those data sources in Snowflake.

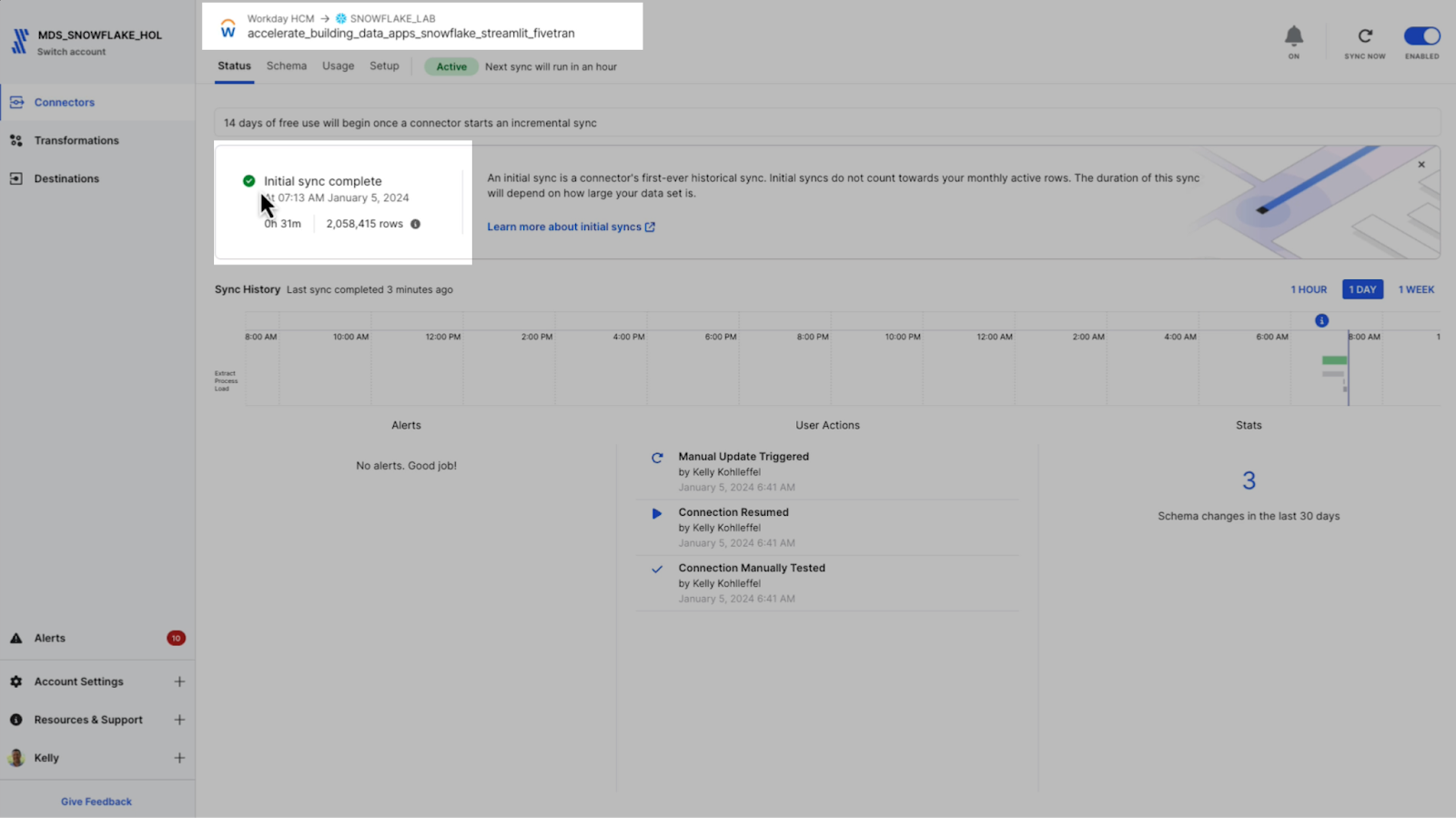
Fivetran status page for the Workday HCM connector (initial sync is complete)
Remember what I named this connector earlier before I move into Snowflake Snowsight to review the new dataset.
accelerate_building_data_apps_snowflake_streamlit_fivetran
Snowflake Snowsight
I opened Snowflake Snowsight and selected the Snowflake database set up for this Fivetran destination. I immediately saw the other connectors, the new Workday schema and the tables Fivetran moved over. Fivetran provides a faithful one-to-one representation of the Workday source data to Snowflake, which is “data app ready.”
The data is organized, understandable and ready to be worked with, enriched, transformed and used in a Streamlit application.
Building a simple talent management data application with Snowflake and Streamlit
Now that Workday HCM is flowing into Snowflake, it’s time to build a Streamlit data app. If you aren't familiar with Streamlit, it's an open-source Python library that makes it easy to create and share custom data apps for machine learning and data science. It’s also available as a native app in Snowflake.
A Streamlit app is a secureable object that adheres to the Snowflake access control framework. Streamlit and Snowflake require a virtual warehouse to run a Streamlit app and perform SQL queries. I’ll walk you through step-by-step how I built my simple Streamlit app.
First, you see, I've got a supply chain efficiency app. The new app will be a simple talent management app that uses the new Workday dataset that I just moved to Snowflake.
I can assign my database and schema to this Streamlit app. Remember, we're operating inside of Snowflake here. Streamlit gives me some “hello world” starter code when the app is first generated.
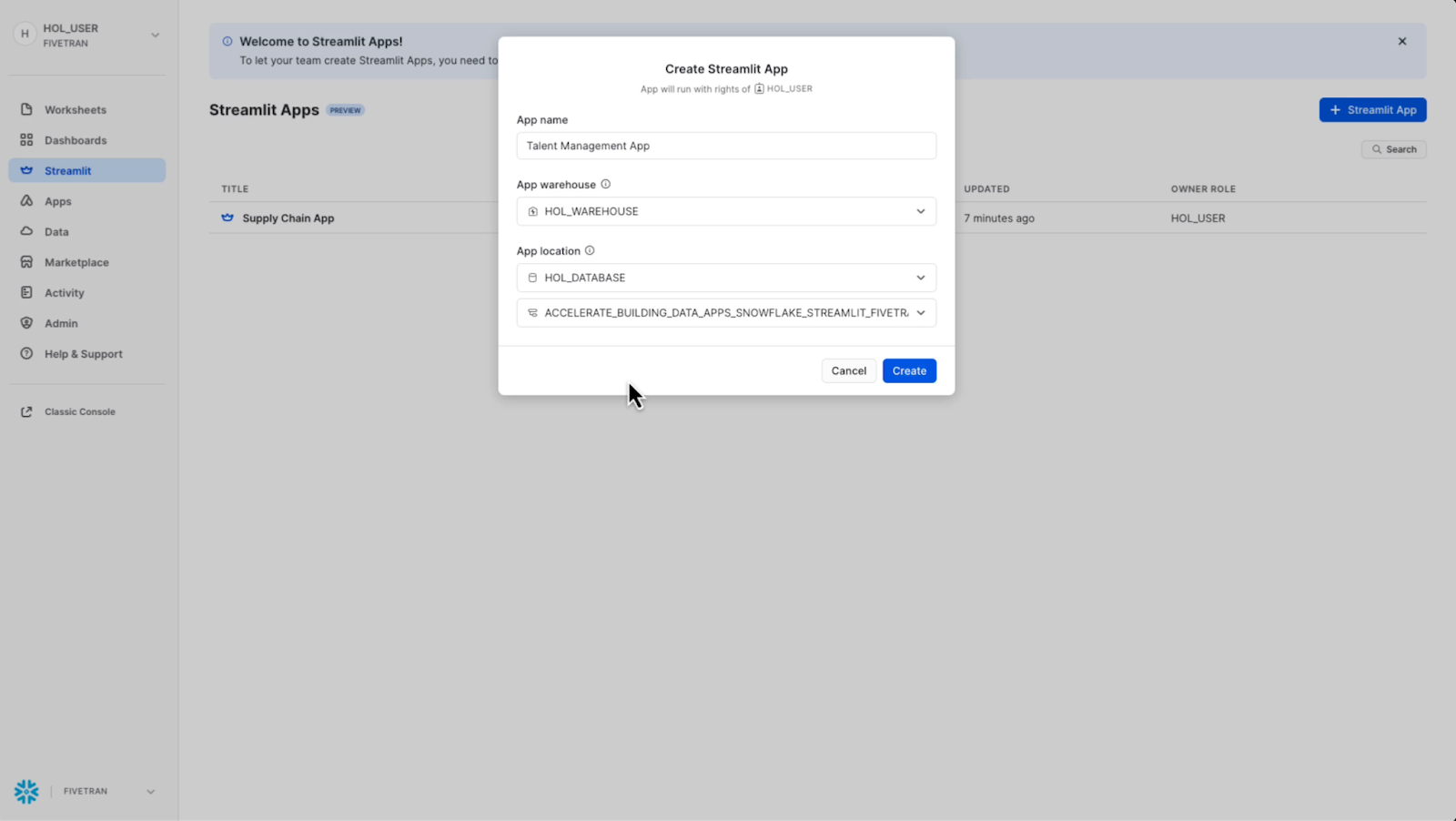
I won’t use much of that today, but it can be helpful to get started. I'm going to start from scratch here. I want to create the foundation for building an interactive Streamlit app that can seamlessly query and display data from Snowflake.
I want to import the Streamlit library and assign the Streamlit alias. This is going to allow me to work with Snowflake connections via Snowpark. This will also store connection details for Snowflake database interactions.
Also, I will run the application, and take a look at it as I go interactively throughout.
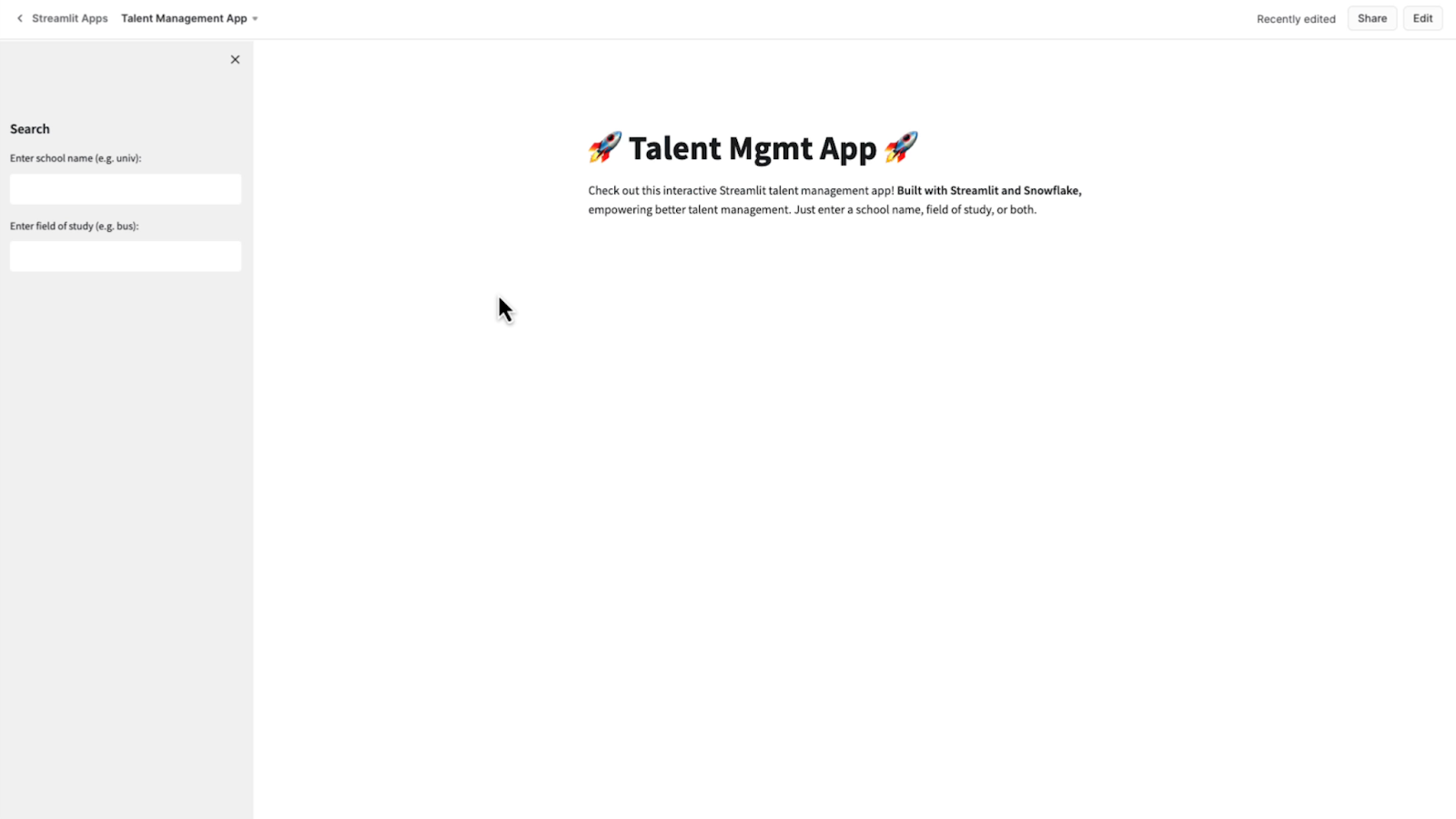
Next, I want to give this application a title and a short description. I’ll add a couple of rocket emojis to the title and just give a simple description of how to use the app.
So let's take a look at it for the first time. I’ll run my Streamlit app and see what I’ve got. So far, so good.
Next, I'd like to have the search on the left side, separated from the results. So I’ll create a min-max section for my search filters in a sidebar, keeping it separate from the results.
I’ll add a search heading and also a couple of search fields. I want to be able to search for the school name and the field of study for this particular application.
I’ll take another quick peek. So far, so good. I’ve got my title and description, and now my sidebar with the search boxes is ready to go.
Let's go back and add the next section of code for attribution and a way to contact me if somebody would like to. Also, I'd like to add the Streamlit logo.
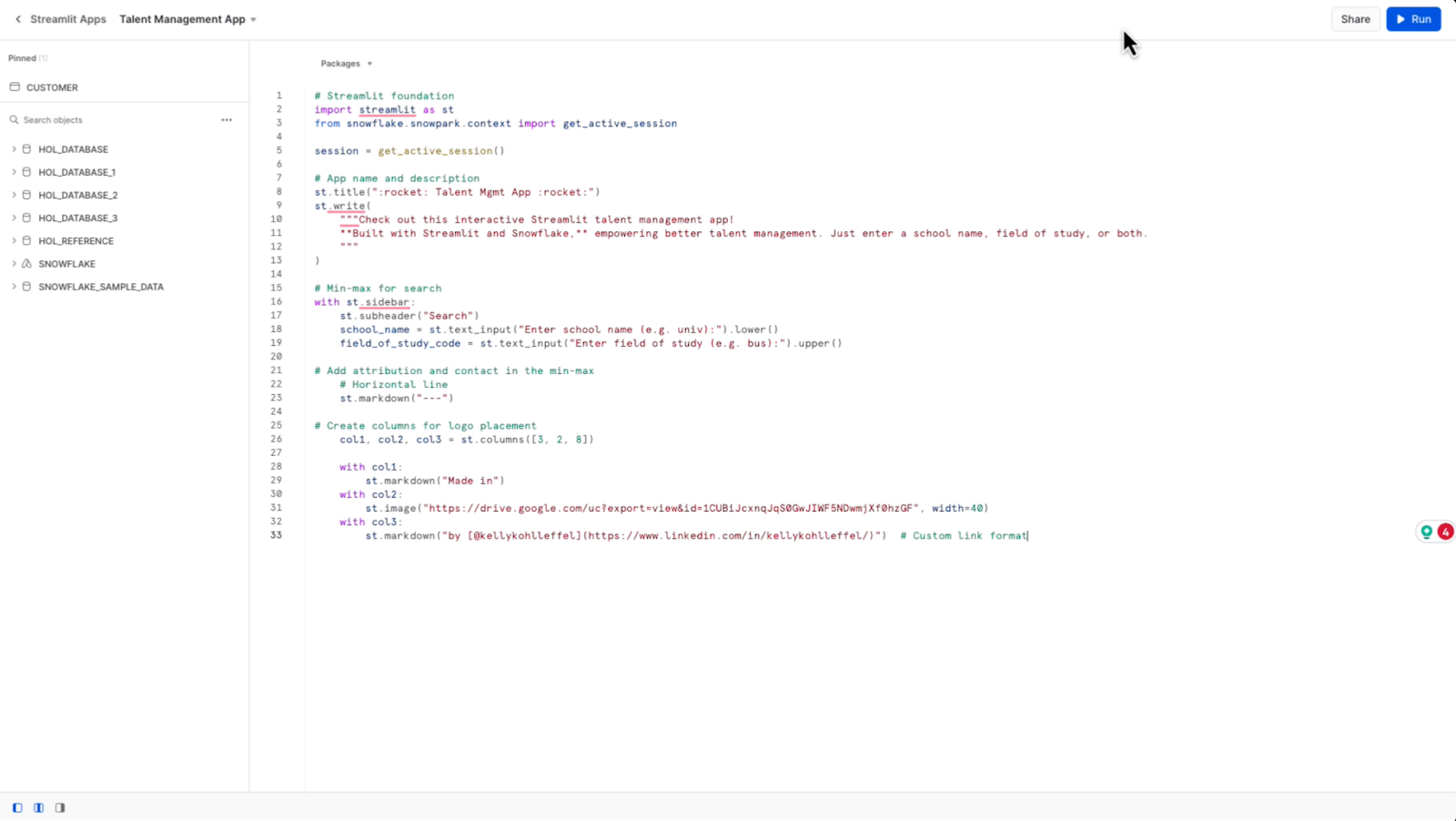
All right. There is the attribution and I’ve got my name in there for contact if needed.
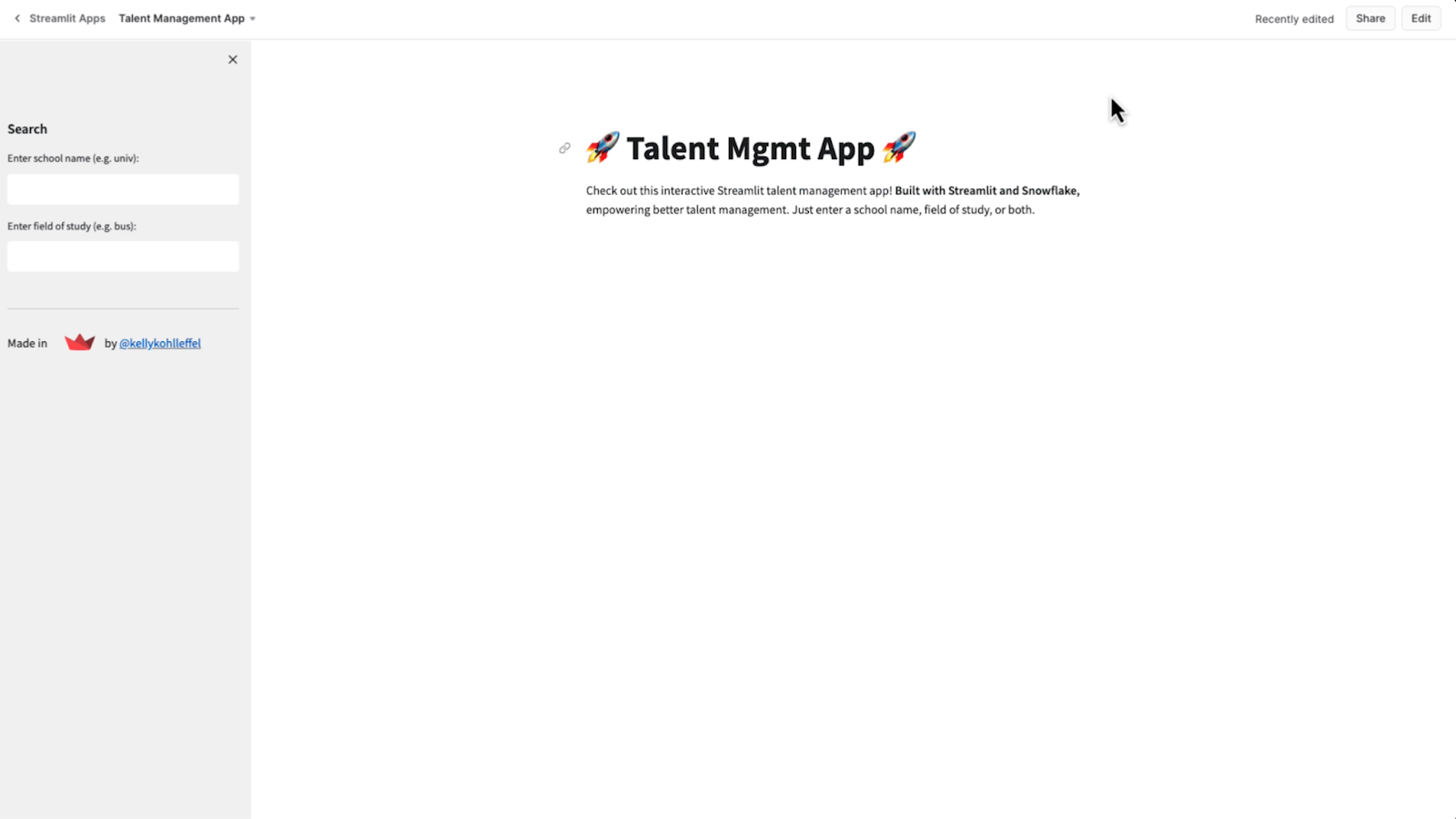
It's not perfect, but it's close enough.
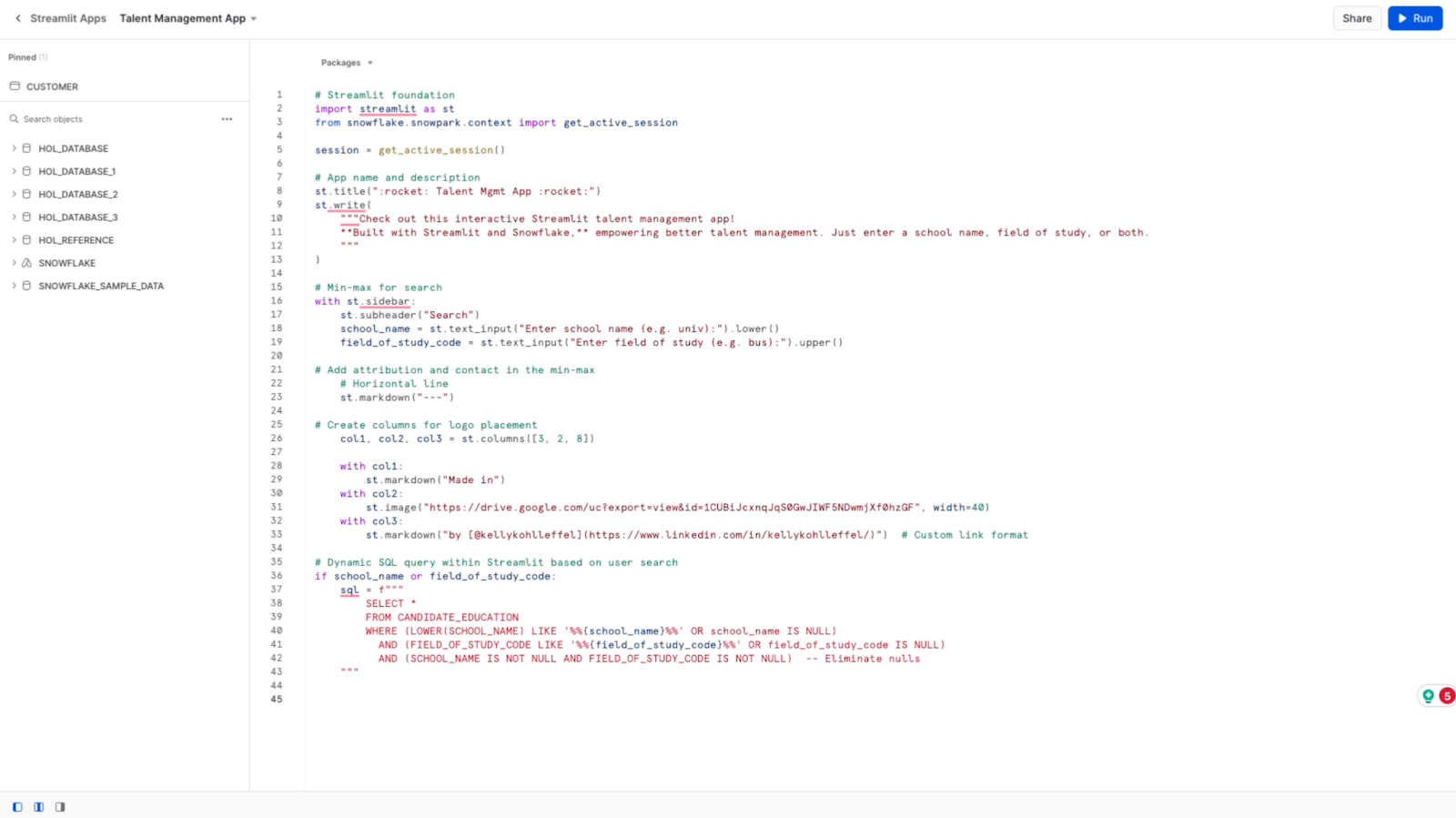
All right, let's add our next section of code here. This will be the foundation for my simple talent management app.
It's a dynamically constructed SQL query within Streamlit based on user input. It needs to have flexible and interactive data filtering. The data set is from the candidate education table you saw earlier.
I want to return all columns in that table. I'm also interested in conditionally searching for candidates based on the school they attended, and I want that to be case-insensitive.
I'd also like to be able to search on their field of study and do partial searches with no nulls returned in the search results.
Next, I want to instruct the application to execute the SQL query, retrieve the results and store them in a Python data frame object. Since our results will be tabular, that makes the most sense. This will convert the data retrieved from Snowflake by Streamlit into a Pandas data frame.
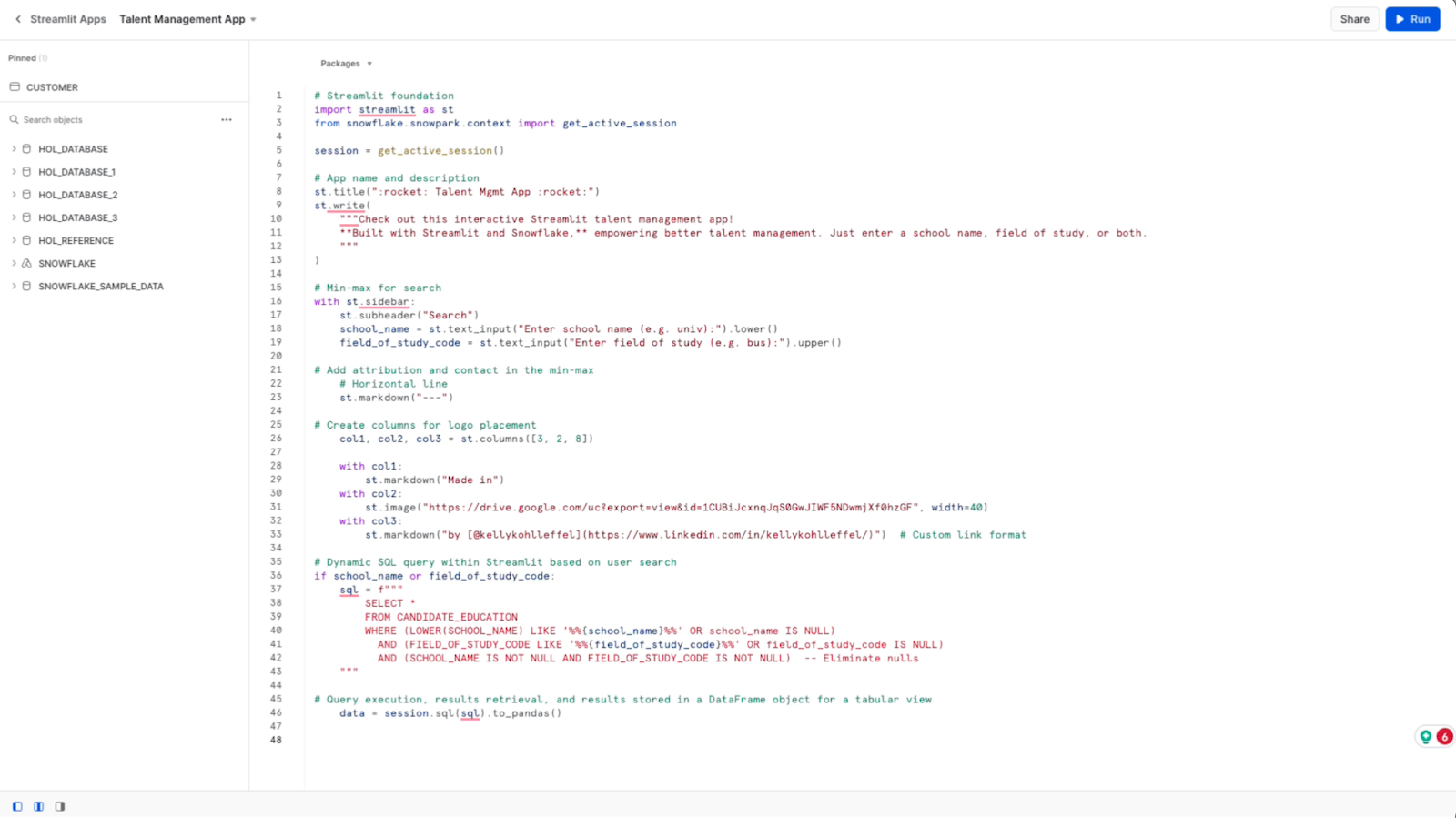
All right, the last thing is to let the user know if the school or the field of study they enter into the search is outside the data set. If they get a hit on a search, the results are displayed using Streamlit's st.dataframe function to render those query results in the main content area of the app.
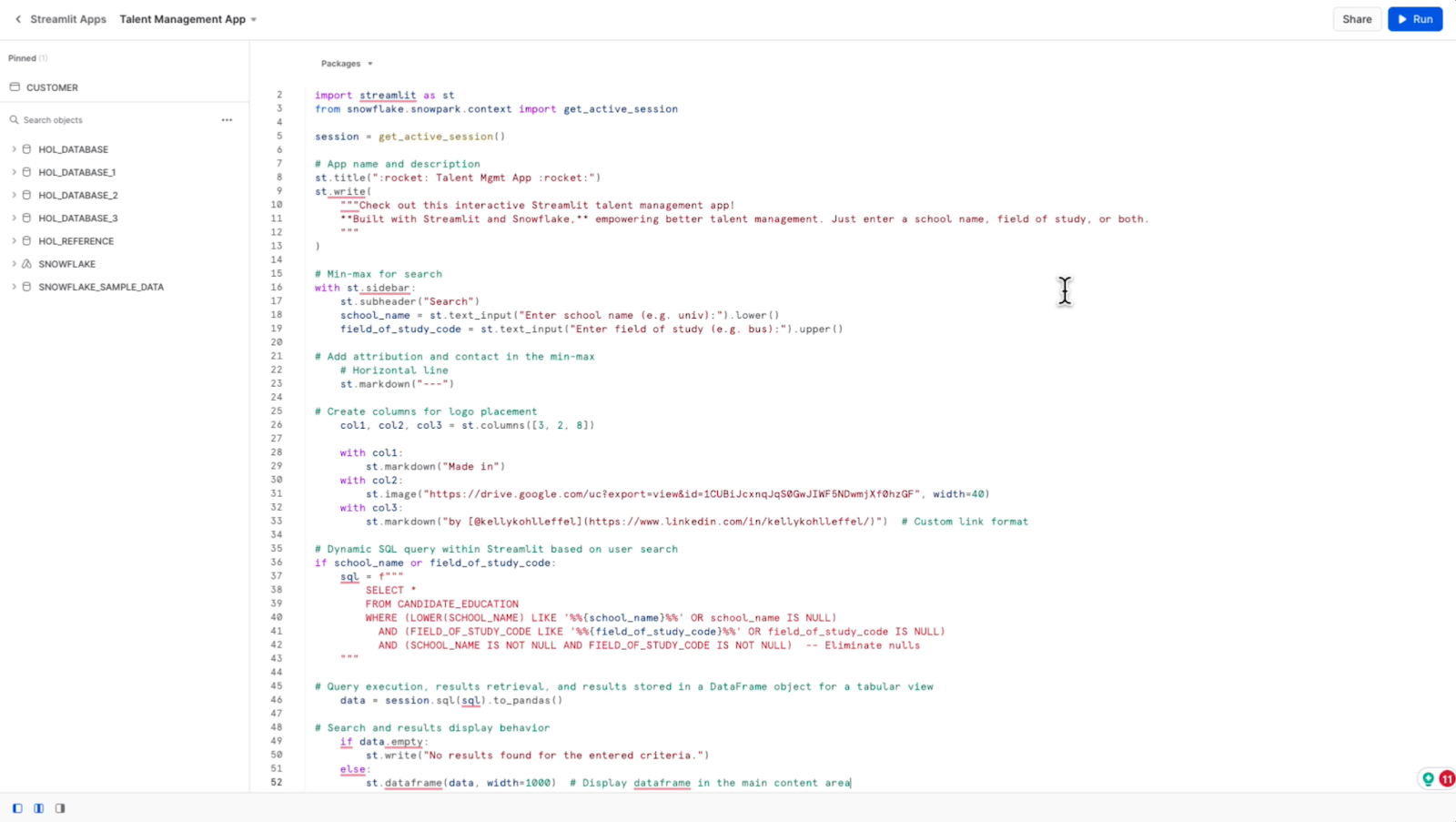
So that's it. I mentioned it was a pretty simple application. Moment of truth now. I’ll run the app and see what I’ve got. Visually, it looks pretty good. I like the way that Streamlit has rendered this.
I’ll do a search now, and, I can search on a partial school name. In this case, “minn”.
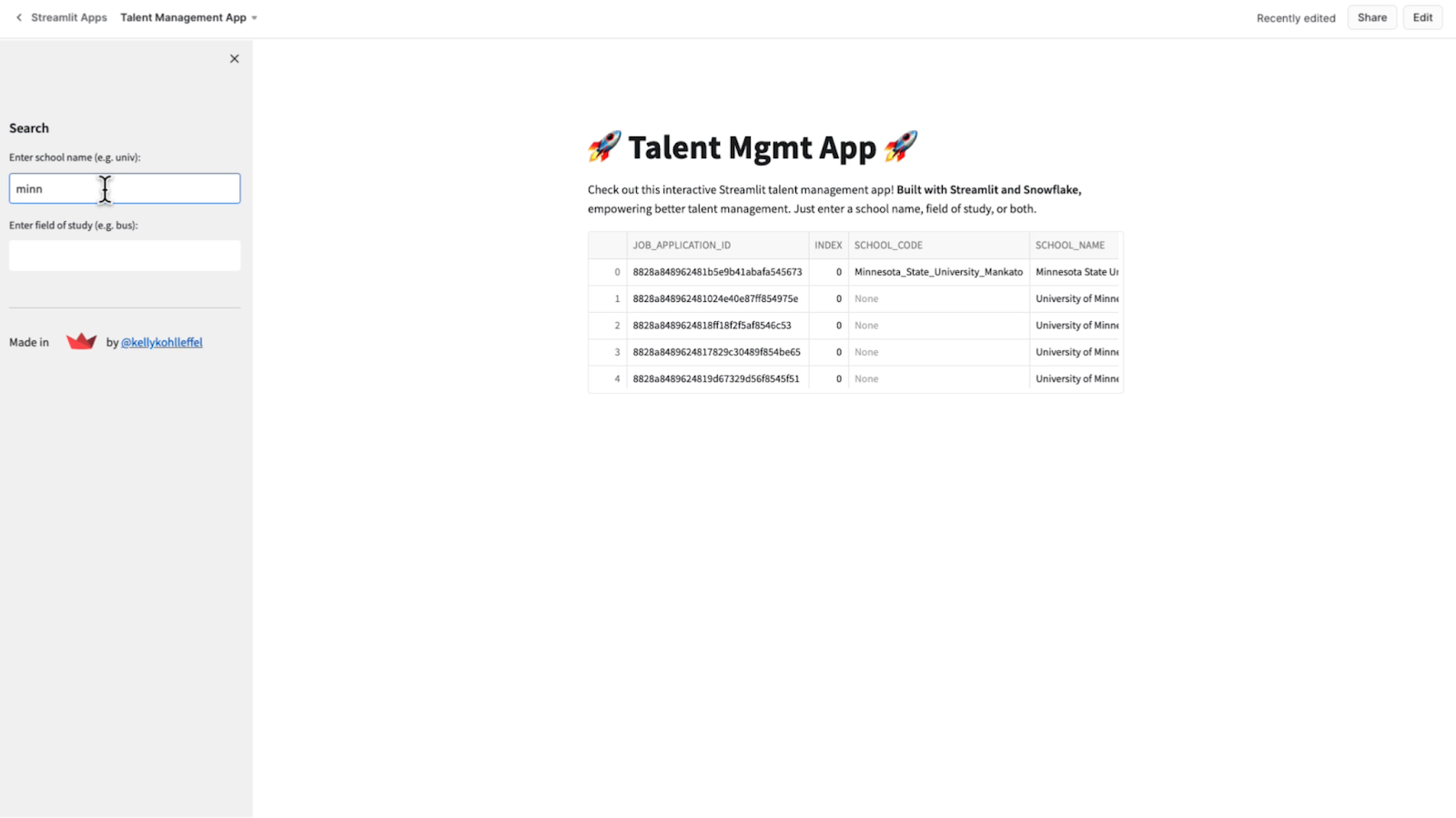
I see the University of Minnesota and Minnesota State University. Also, a field of study can be partial. So for finance (fin), for instance.

I could search on business or geology or whatever field of study I wanted for candidates here. So all of that is looking good.
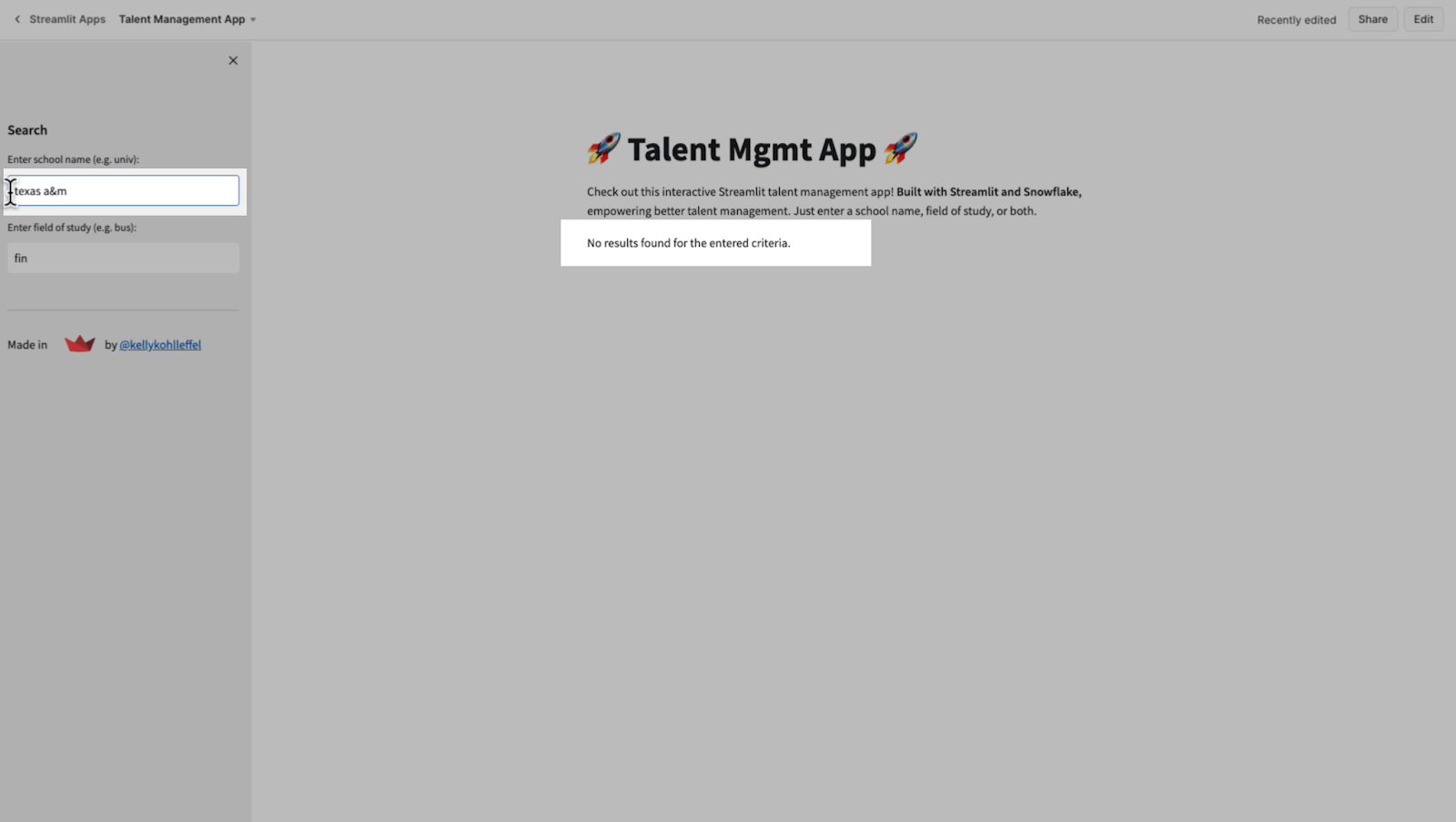
I’ll try another one. Texas A&M is my alma mater. Nope. There is nothing from Texas A&M in that data set, at least no candidates with finance degrees.
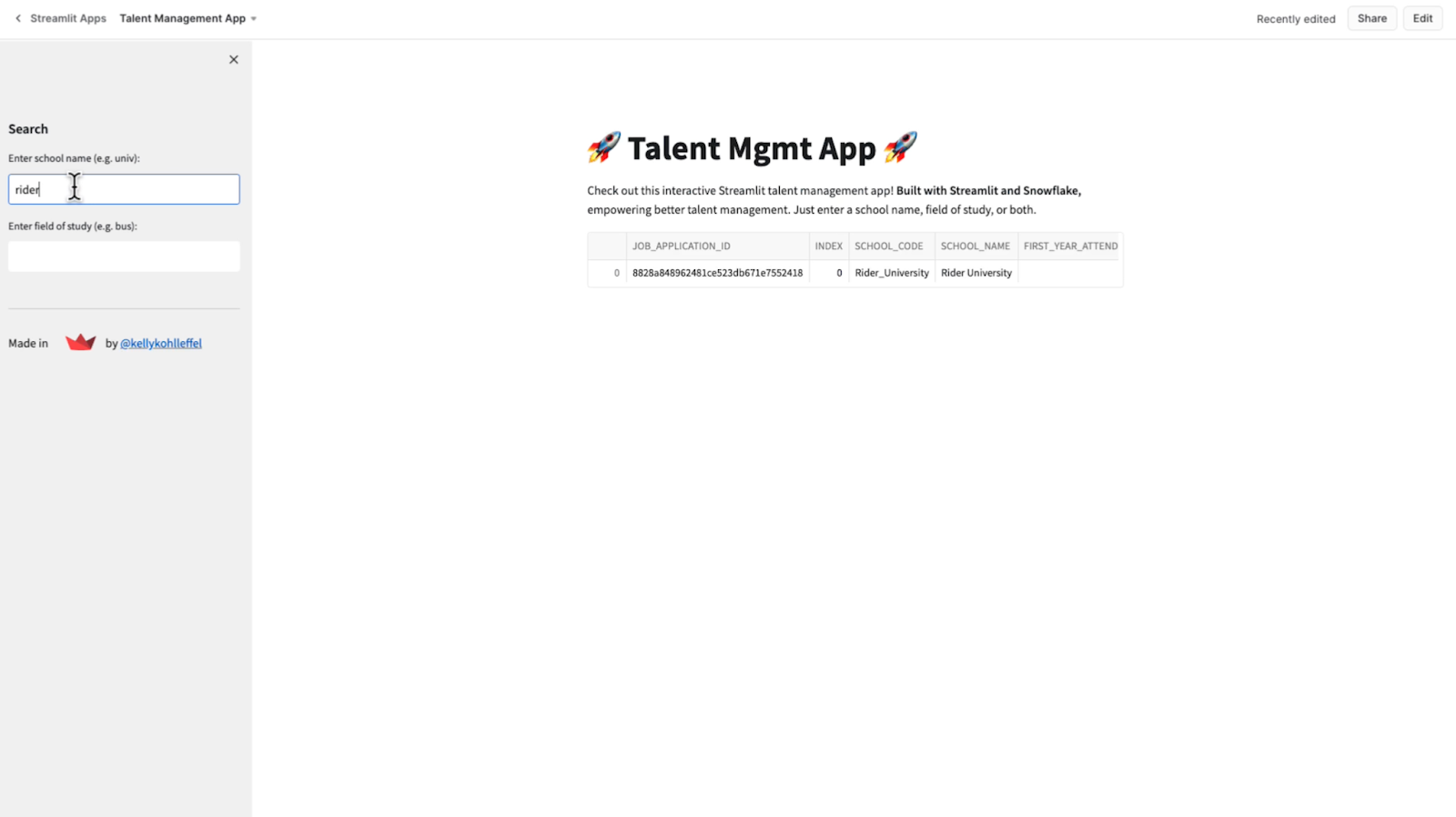
One more search. How about Rider University? Got a hit, but not with a finance degree. The candidate from Rider studied business administration.
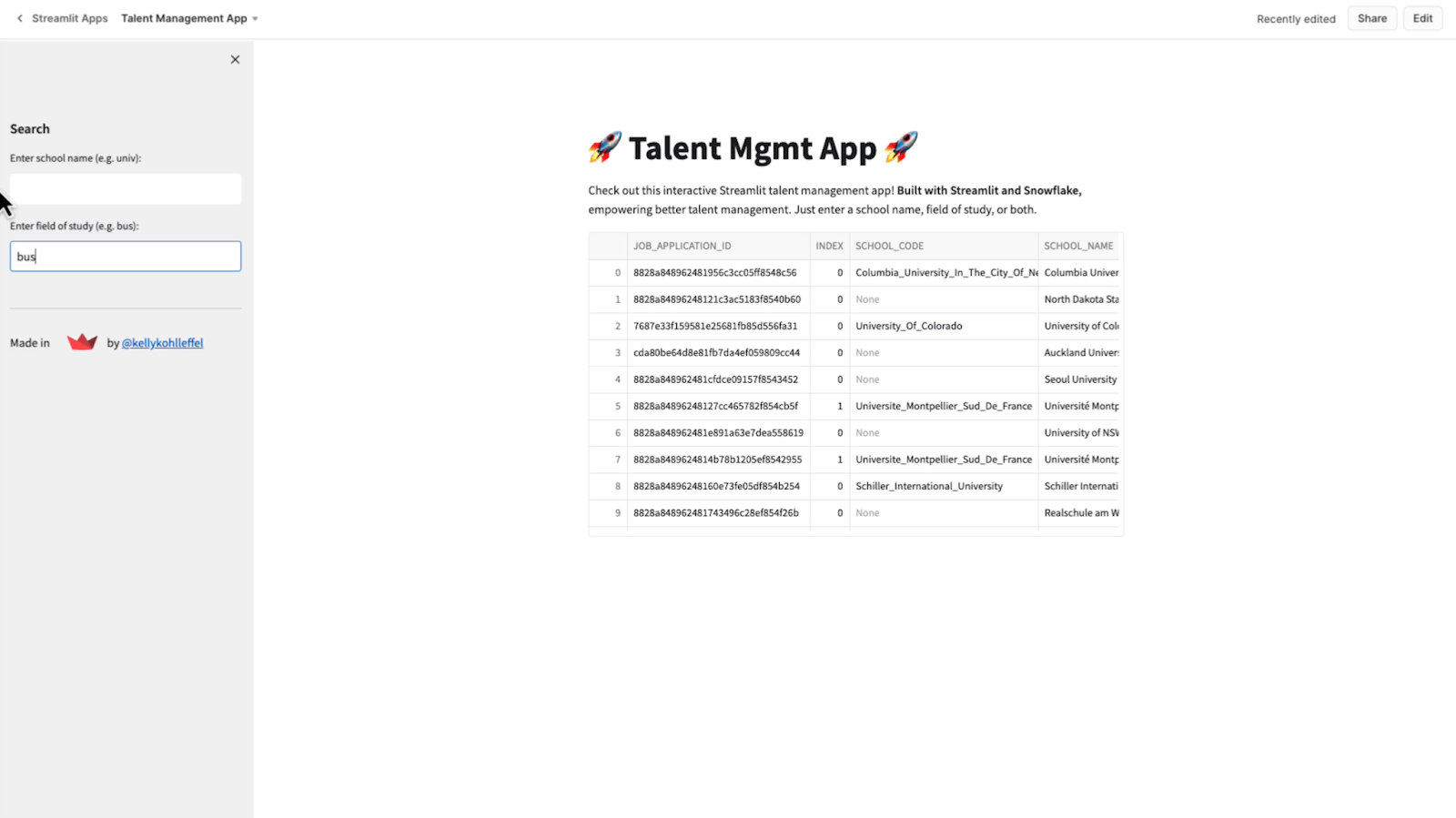
I’ll just search on the field of study I’m interested in, BUS for business, and see what that gives me.
That search resulted in several school names. We're not getting any nulls in those school names or in that field of study code. I’m pretty happy with this application overall and Streamlit's functionality based on the Workday dataset.
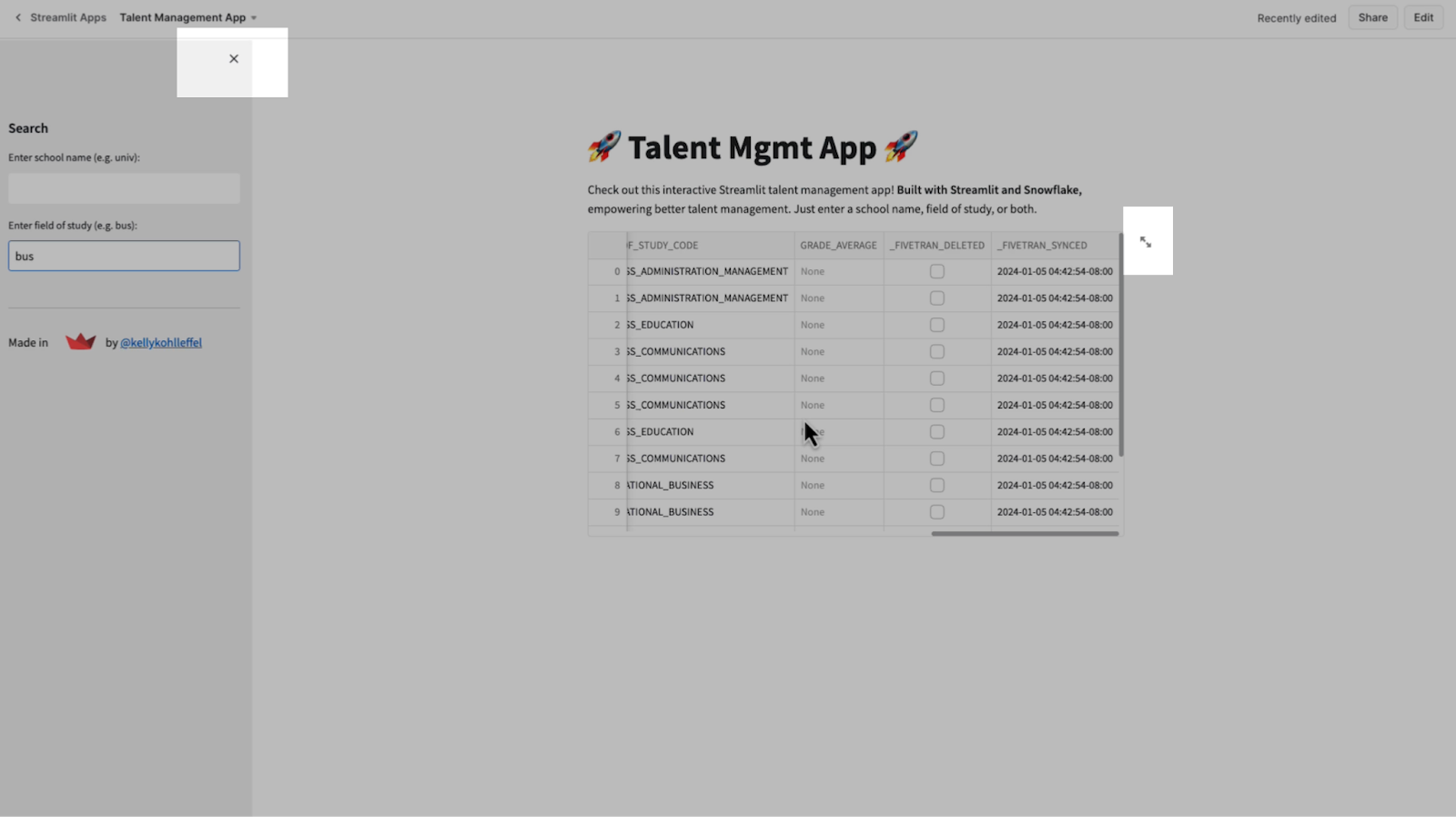
The app also has a min/max on the sidebar and another on the results set. Streamlit makes it extremely easy to configure these applications and adjust them to your desired user experience.
Talent management may be a stretch, but you get the idea.
Snowflake Partner Connect with Fivetran makes it easy to connect
If you don't have a Fivetran account right now, you can set up a Fivetran trial account quickly and easily right from Snowflake Partner Connect.
In fact, Snowflake automatically creates the required objects for you, including the Snowflake database, the warehouse, the system user and the system roles that Fivetran requires to connect to Snowflake. It’s very easy, and I encourage you to check it out.

Get started now
Snowflake, Streamlit and Fivetran together. You get high-quality, usable, trusted data into Snowflake, which can immediately be used to build any Streamlit application you can imagine.
Fivetran ensures that data movement to Snowflake is standardized and predictable across any data source. Each fully automated and fully managed pipeline provides reliability, scalability, predictability and security. If you'd like to discuss your requirements for moving Workday HCM or over 500 other data sources simply and reliably into Snowflake, Fivetran offers a 14-day free trial.
It would be great to hear from you on any connectors, data workloads and industry use cases you’d like to see profiled next. Take care!
[CTA_MODULE]










.png)

%20(1).png)
.svg)
.svg)
.svg)