

Data has become a tremendous competitive advantage, and it’s especially valuable in an uncertain economy, helping organizations cope with or even thrive through adversity. Your data team is likely being asked to handle more data from more sources while reducing time to insight — without additional budget or headcount.
In this article, we’ll look at how a cost-effective approach to ELT can help you solve this dilemma, improving analytics outcomes while making your data team — and stack — more efficient. Specifically, we’ll examine four areas that determine how cost-effective an ELT approach is:
- Building data pipelines
- Maintaining data pipelines
- Moving data
- Transforming data
[CTA_MODULE]
1. Building data pipelines: Is DIY worth it?
Many organizations build their own data pipelines, and if you have the in-house expertise, that can seem like a cost-effective solution. It may also give you more control over the flow of your data. There are significant drawbacks, however.
Data engineering opportunity cost
The time required to complete a data pipeline project varies widely. Factors like API complexity and the number of individual data connectors comprising the pipeline can add or subtract quite a few hours, but even modest pipeline projects tend to take weeks or months to complete.
Additionally, because DIY pipelines are not automated and lack self-healing capabilities, they tend to require substantial maintenance after construction. According to a recent survey from Wakefield Research, data engineers spend 44 percent of their time, on average, building and maintaining data pipelines. The majority of data leaders (70 percent) said their engineers would add more value to the business if they could focus on strategic projects instead.
Lack of scalability and business agility
Scalable data pipelines are vital for business growth — and as your company grows, you’ll need to handle more data sources and higher data volumes. It’s not realistic to expect your engineers to build and maintain a connector for every new data source. Onboarding new engineers with DIY pipelines requires significant knowledge transfer. For pipelines connected to API’s, new engineers have to read the API documentation and understand how the code is written to understand their behavior (retry logic, API throttling limits, etc). For database pipelines, the new hire has to understand the schema and, similarly to API pipelines, understand the code to understand the behavior (retry logic, credential management, etc).
The efficiency penalty of open-source data pipelines
An alternative to manual coding is using an open-source connector development kit (CDK), which can speed up the build process. You will still run into a host of inefficiencies, however — and there may also be hidden costs. Here are the main shortcomings to be aware of:
- Bugs and inadequate data
- Lack of automation and low data quality
- Hidden infrastructure and compute costs
- Lack of support
2. Maintaining data pipelines: If I buy, will I still have to fix connectors?
As you think about ELT cost-effectiveness, pipeline reliability is a critical factor to consider. Pipeline breaks due to data source changes can have serious downstream impacts and take hours or days to repair. Look for ELT solutions that address schema and API changes automatically.
Schema changes
Even a small schema change can have disproportionately large downstream effects — it may take many hours to change the affected transformations, manually edit the destination schema so new data can flow through, etc. In the meantime, dashboards that functional teams rely on may break and incomplete or inaccurate data may appear in reports.
Fivetran eliminates these issues by automatically detecting and responding to source schema changes.
API changes
When API data models change, Fivetran rapidly addresses those changes in the connector code, sparing your team the time cost of broken pipelines, the pain of late nights/early mornings performing repairs and the business impact of inaccurate or outdated metrics.
3. Moving data: What are the key attributes of a highly efficient data pipeline?
Eliminating pipeline maintenance will help your team get more done, but ELT platforms can also deliver meaningful efficiencies when it comes to moving and managing data. Let’s take a look at best-practice data engineering across five key capabilities.
Data normalization
Designing a schema that delivers accurate, comprehensive data is quite painstaking and time-consuming — and the process is partially repeated each time the underlying data model changes. Fivetran schemas provide nearly everything you need to know to work with a data set:
- The tables represent business objects
- The columns represent attributes of those objects
- Well-named tables and columns are self-describing
- The primary and foreign key constraints reveal the relationships between the business objects
Fivetran also normalizes your data in our own VPC, so you’ll never have to worry about data ingestion processes devouring your warehousing compute bill.
Idempotence
Sync failures are inevitable, and recovering from them requires rolling back to a previous cursor and reintroducing some number of records to a destination. Without idempotence, this reintroduction will cause records to be duplicated, undermining the integrity of the data repository. Fivetran uses an idempotent recovery process, meaning every unique record is properly identified and no duplication occurs when syncs restart after failures.
Incremental syncs
Full syncs are necessary to capture all your data initially, but they’re inappropriate for routine updates because they often take a long time, bog down both the data source and the destination, and consume excessive network bandwidth. Make sure your data movement provider syncs data incrementally — and does so in a way that solves the common problems associated with incremental syncs.
Data selection
Your team might not be interested in analyzing the data in every single table an ELT provider syncs by default into your destination — and if those tables are large, they can significantly increase your data integration and warehousing costs. Efficient ELT platforms allow you to granularly de-select tables and columns:
.png)
Programmatic pipeline management
The ability to manage data pipelines via an ELT provider’s API can hugely reduce your team’s workload — and it’s essential for anyone trying to build data solutions at scale. The Fivetran API allows you to perform bulk actions, communicate with Fivetran from a different application, and automate human-led processes using codified logic. We’ve helped customers use the Fivetran API to create connectors to hundreds of databases — and in one instance over 1,000 — saving them many hours of work in the process. You can also use it to create powerful data products for your customers.
4. Transforming data: How can an ELT platform accelerate analytics?
Ideally, an ELT tool or platform takes an integrated approach to the “T,” making data transformation as simple and powerful as possible within its own UI. Here are the features you should look for in terms of integrated transformations, many provided by dbt™, the leading SQL-based transformation tool. Fivetran’s transformation layer integrates with dbt and provides additional features to accelerate your analytics.
Version control
Dbt Core offers a full change history of your transformation models, making troubleshooting and validating data integrity far more efficient. You can easily revert transformation models back to previous versions if needed and compare changes over specific periods of time.
Prebuilt data models
Prebuilt data models reduce the need to manually code SQL, saving your data team weeks of time. You’ll be able to focus on deeper analysis and generate insights faster instead of doing foundational data modeling. Fivetran offers an extensive library of open-source data models for supported data sources.
Modularity
With dbt, you can reproduce a transformation across multiple models and handle the dependencies between models. For example, if you have a “product” model that joins a product table to a category table, you can reuse this model across all relevant data sources — minimizing the need to build code from scratch.
Data lineage graphs
Fivetran automatically generates data lineage graphs, which provide a full visual representation of a transformation from source to output model, including status and logs. Visually exposing complete workflows makes it easy to track the flow of data, monitor performance and quickly debug models in the pipeline to avoid data latency.
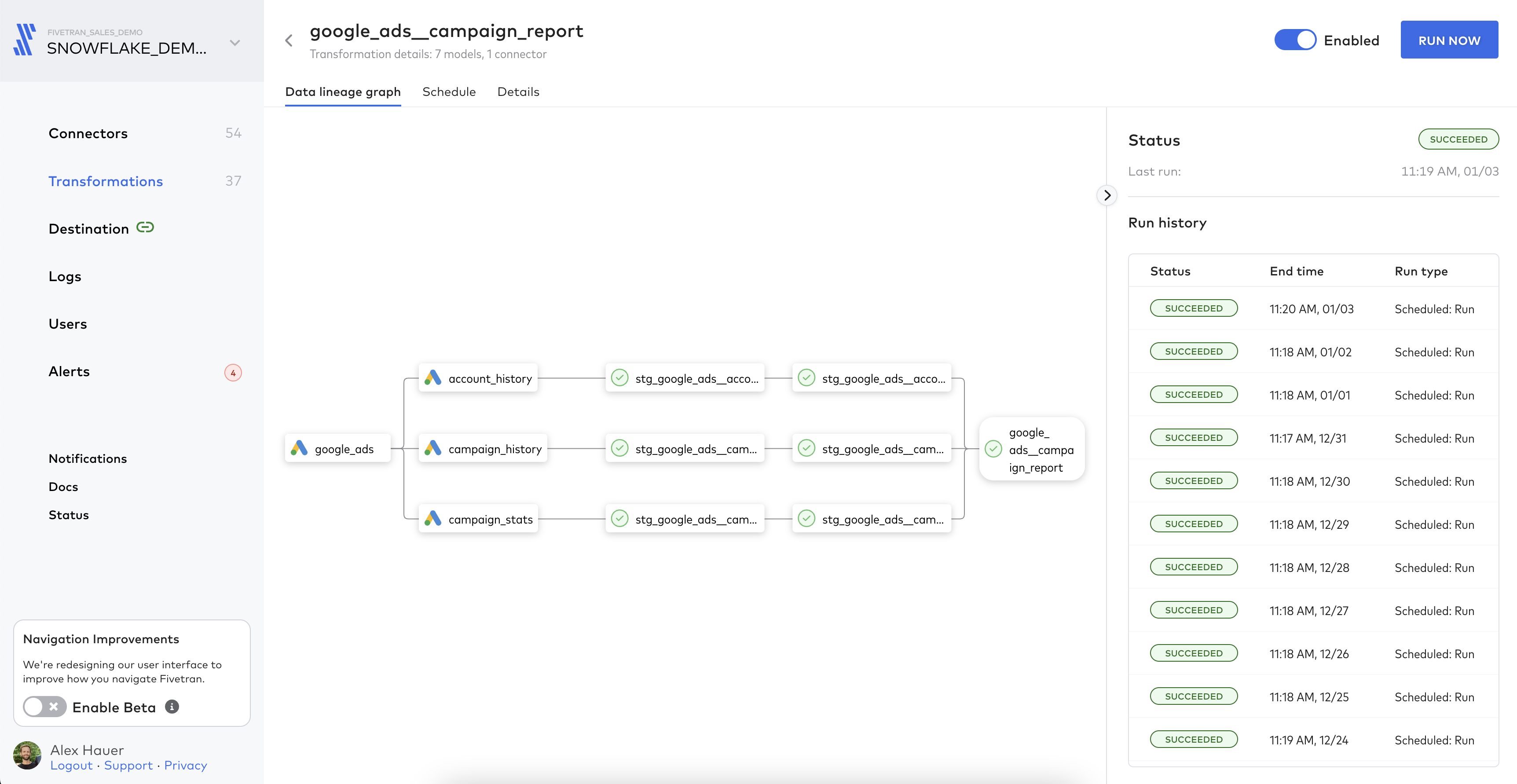
Scheduling and managing transformations
Getting started with Fivetran Transformations is as easy as connecting a Git repository with an existing dbt Core project in it. You’ll have the option of choosing which models you want us to manage and how you want to schedule them. We will constantly sync with the Git provider, ensuring that all updates are reflected in your models.
Importantly for teams looking to save time and keep data fresh, Fivetran offers what is known as “fully integrated” scheduling — by default, your new transformations are synchronized with their associated connectors.
Dive deeper into ELT cost-effectiveness
At Fivetran, we’ve spent over a decade solving these kinds of data movement and transformation challenges. In the process, we’ve developed a range of features that make life a lot easier for your data team while reducing your data stack costs.
For a more in-depth discussion of these features — and of ELT cost-effectiveness generally — take a look at our recent ebook, How to choose the most cost-effective data pipeline for your business.
[CTA_MODULE]











%20(1).png)

.svg)
.svg)
.svg)